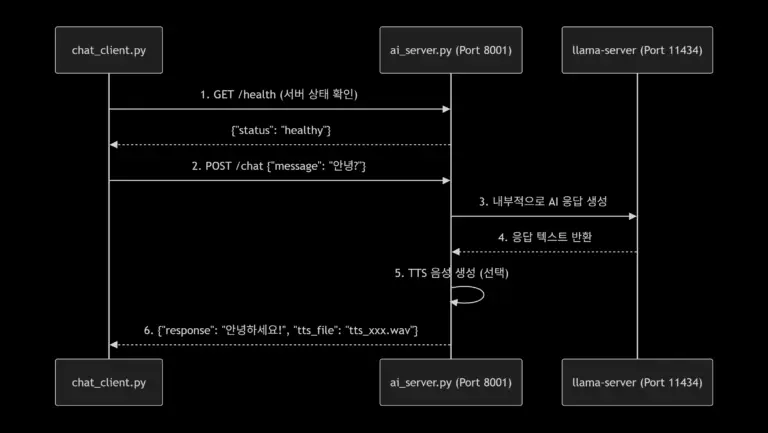
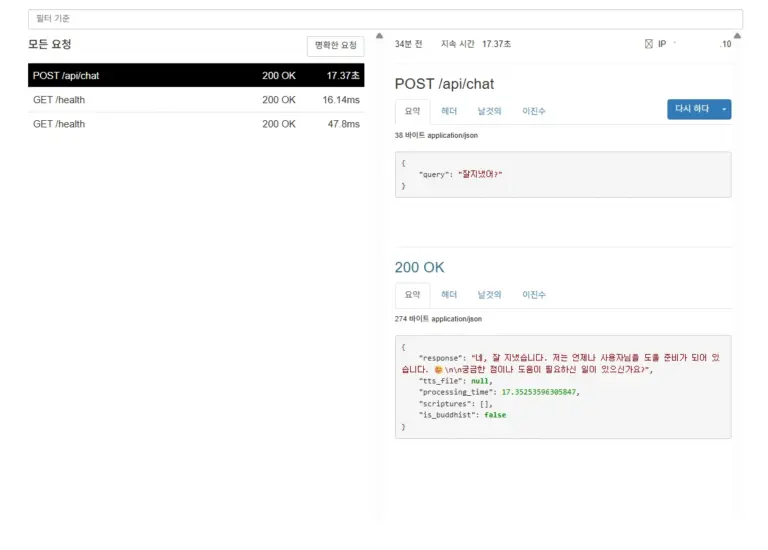
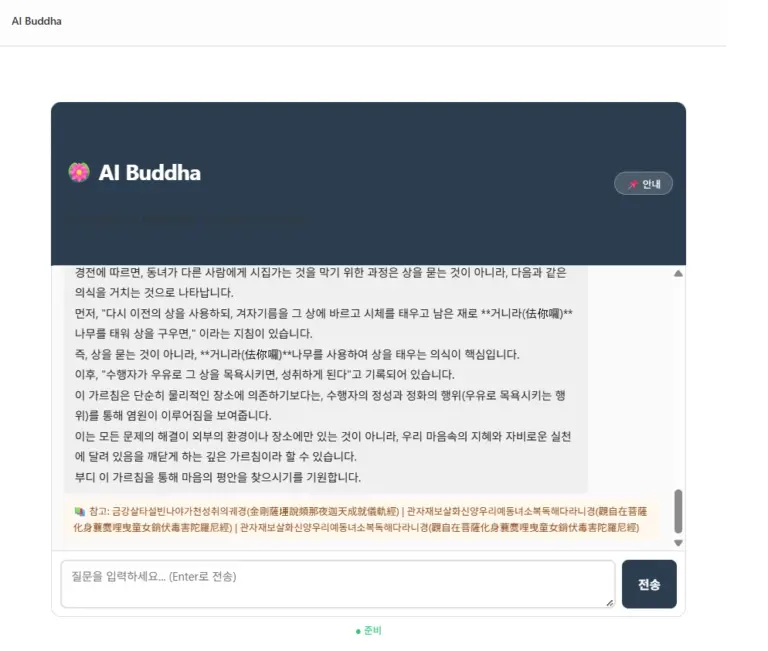
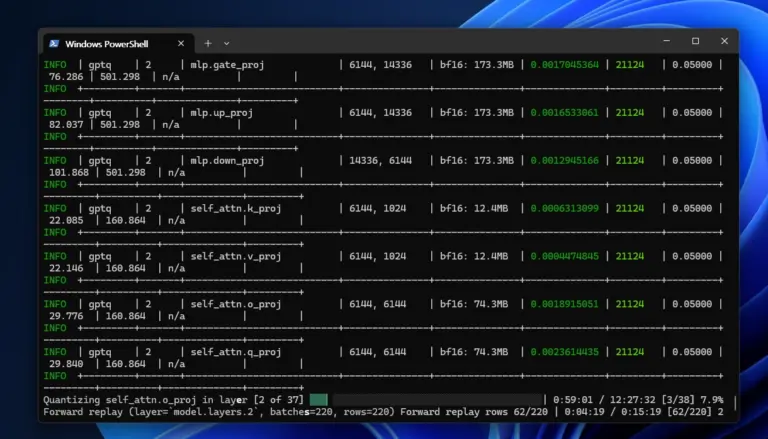
연속 파인튜닝(Continual Fine-tuning) 가능할까? OpenAI와 오픈소스 LLM 비교
2026-07-25 – 9:19 오전
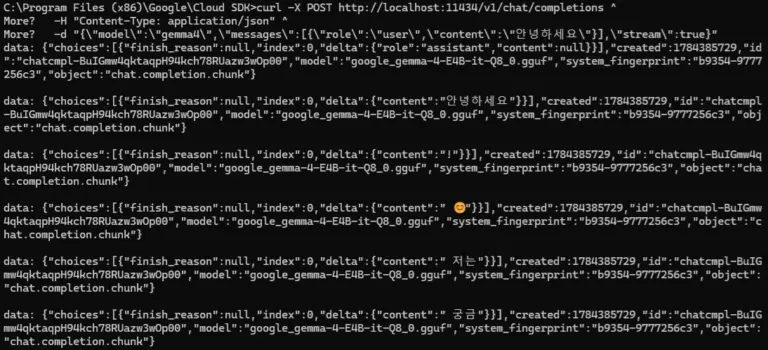
연속 파인튜닝(continual fine-tuning)이 모든 AI 모델에서 가능한지, OpenAI 같은 상용 API와 Llama·Mistral 같은 오픈소스 모델은 어떻게 다른지 비교합니다. 파인튜닝 이어하기 시 반드시 마주치는 재앙적 망각(Catastrophic Forgetting) 문제와 통합 데이터셋 재학습이라는 실무 해결법까지 단계별로 정리했습니다. 1. “파인튜닝한 모델에 데이터를 더 넣고 싶은데요” 이미 한 번 파인튜닝을 마친 모델이 있는데, 시간이 지나 새로운 데이터가 쌓이면 자연스럽게 이런 […]