거대 언어 모델(LLM)은 수십 GB에 달하고 그 AI 모델 파일은 일반적인 그래픽카드(GPU) 메모리에 담기엔 너무나 큽니다. 이때 필요한 것이 바로 양자화(Quantization)입니다.
특히 오늘 우리가 함께 알아볼 방식은 GPTQ 양자화(Generalized Post-Training Quantization) 기법입니다. 이 방식은 모델을 처음부터 다시 학습할 필요 없이, 이미 학습이 완료된 모델의 가중치(Weight)를 정밀하게 분석하여 16비트(또는 bf16)의 무거운 데이터를 4비트의 가벼운 데이터로 압축하는 ‘사후 보정’ 방식입니다.
모델의 구조를 파괴하지 않으면서도 연산 효율을 높일수 있어, 표준화되지 않은 독자적인 구조의 AI 모델을 다룰 때 가장 강력하고 범용적인 해결책이 되어줍니다.
오늘은 복잡한 이론은 빼고, 내 PC의 그래픽카드 메모리를 효율적으로 사용하여 AI 모델을 압축하는 양자화(Quantization) 환경 설정 및 실행 방법을 GPTQ방식으로 알아보고 정리해 드립니다.
목차
1. GPTQ 양자화 준비물
가장 먼저 본인의 PC 환경을 확인해야 합니다.
- 운영체제: 윈도우 10/11
- 그래픽카드: NVIDIA GPU (VRAM 8GB 이상 권장)
- 소프트웨어: Python 3.10 이상, Git 설치
2. 가상환경 설정하기
여러 라이브러리가 섞이면 에러가 발생하기 쉽습니다. 프로젝트별로 독립적인 공간을 만들어줍니다.
- 폴더 생성: 명령 프롬프트(CMD)나 파워쉘(PowerShell)을 열고 작업할 폴더로 이동합니다.
mkdir AI_Study
cd AI_Study - 가상환경 만들기: 파이썬 내장 기능을 사용합니다.
python -m venv venv - 가상환경 활성화:
.\venv\Scripts\activate
(창 앞에(venv)가 보이면 성공입니다.)
3. GPTQ 양자화 필수 라이브러리 설치
양자화에 필요한 핵심 도구들을 설치합니다.
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install gptqmodel datasets transformers
pip install optimum
gptqmodel: 모델 양자화 핵심 라이브러리datasets: 모델 학습/보정에 필요한 데이터셋 관리 도구transformers: 허깅페이스 모델 로드 및 조작 도구
필요한 라이브러리 및 버전 정리
모델을 GPU로 로드하기 위해 필요한 구성은 다음과 같습니다.
| 라이브러리 | 필수 버전 | 이유 |
| PyTorch (torch) | 2.8.0+cu124 이상 | gptqmodel 7.0.0의 실행 필수 조건 |
| CUDA Toolkit | 12.4 | PyTorch cu124와 호환되는 드라이버/툴킷 |
| gptqmodel | 7.0.0 | 현재 사용 중인 양자화 모델 라이브러리 |
| torchvision/audio | torch와 동일 버전 | 의존성 오류 방지를 위한 세트 설치 |
4. AI 양자화 코드 작성 및 실행
이제 모델을 압축하는 파이썬 코드(quantize.py)를 만듭니다.
import os
import torch
from gptqmodel import GPTQModel, QuantizeConfig
from datasets import load_dataset
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:128"
model_path = "G:/AI_Study/Ai_model/HyperCLOVAX-SEED-Think-14B"
output_path = "G:/AI_Study/Ai_model/HyperCLOVAX-SEED-Think-14B-GPTQ"
quant_config = QuantizeConfig(bits=4, group_size=128, desc_act=False)
print("모델 로드 시작...")
model = GPTQModel.from_pretrained(
model_path, quantize_config=quant_config, device_map="auto", trust_remote_code=True
)
# 모든 선형 레이어의 차원을 강제로 출력하여 검증
print("\n--- [로그] 모든 레이어 차원 전수 검사 시작 ---")
for name, module in model.model.named_modules():
if hasattr(module, "in_features"):
before = module.in_features
# 어떤 차원인지 모든 레이어의 이름을 찍어 확인합니다.
print(f"[검사] 레이어: {name} | 감지된 in_features: {before}")
if before == 14334:
print(f" >>> [보정 대상 발견] {name} 레이어를 14336으로 수정합니다.")
module.in_features = 14336
if hasattr(module, "g_idx") and module.g_idx is not None:
padding = torch.full(
(2,),
module.g_idx[-1],
device=module.g_idx.device,
dtype=module.g_idx.dtype,
)
module.g_idx = torch.cat([module.g_idx, padding])
print(f" └─ 성공: {name} g_idx 보정 완료.")
print("--- [로그] 전수 검사 종료 ---\n")
print("보정 데이터셋 준비 중...")
traindata = load_dataset("wikitext", "wikitext-2-raw-v1", split="train")
dataset = [text for text in traindata["text"] if len(text) > 0][:300]
print("양자화 시작...")
try:
model.quantize(dataset, batch_size=1)
print("[성공] 양자화 연산이 차원 오류 없이 완료되었습니다.")
except Exception as e:
print(f"[오류] 양자화 도중 차원 정렬 실패: {e}")
raise e
print("모델 저장 중...")
model.save_quantized(output_path)
print("양자화 완료!")
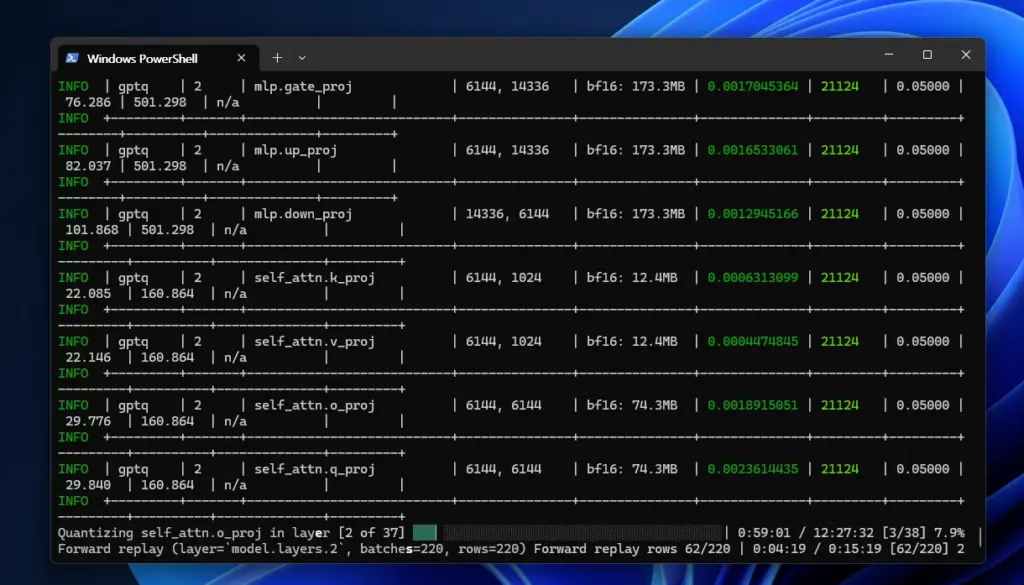
5. GPTQ 양자화 실행 및 확인
작성한 코드를 실행합니다.
python quantize.py
화면에 모델의 레이어(Layer)들이 하나씩 4비트로 변환되는 과정이 표 형태로 출력됩니다. 완료되면 지정한 경로에 가벼워진 모델 파일이 생성됩니다.
이 과정을 통해 수십 GB에 달하던 거대 모델이 1/4 크기로 줄어들어, 개인용 GPU에서도 원활하게 돌아가게 됩니다.
- 성능 유지: 보정 데이터셋을 사용하여 양자화 후에도 모델의 지능은 거의 그대로 유지됩니다.
- 비용 절감: 값비싼 서버를 빌릴 필요 없이, 내 PC에서 자유롭게 AI 연구와 개발이 가능해집니다.
HyperCLOVAX-SEED-Think-14B-quantize.py 양자화 파일
HyperCLOVAX-SEED-Vision-Instruct-3B-q4_k_m.ggu 양자화 파일