양자화 방식은 생각보다 훨씬 다양합니다. 보통 GPTQ, AWQ, GGUF가 현재 가장 대중적인 3대장인 것은 맞지만, 기술의 발전과 목적에 따라 새로운 방식들이 계속 등장하고 있습니다. 양자화(Quantization)란 무엇인가?
쉽게 비유하자면 ‘사진 용량을 줄이는 과정’과 같습니다. 4K 고해상도 원본 사진(16bit 또는 32bit 정밀도)을 적당한 화질의 JPEG(4bit)로 압축하는 것이죠.
모델의 파라미터는 보통 float32라는 고정밀 숫자로 표현됩니다. 하지만 이 숫자를 int4(4비트 정수) 같은 더 낮은 정밀도로 바꾸면, 모델의 파일 크기는 1/4 수준으로 줄어들고 GPU 메모리 사용량도 획기적으로 낮아집니다. 약간의 정밀도 손실이 발생할 수 있지만, 요즘 기술은 모델의 성능을 거의 유지하면서도 메모리 효율을 최적화하는 수준까지 올라왔습니다.
인공지능 모델, 특히 하이퍼클로바X와 같은 거대 언어 모델(LLM)을 개인 PC에서 돌려보고 싶다는 생각, 다들 한 번쯤 해보셨죠? 하지만 수십 GB에 달하는 모델 파일은 일반적인 그래픽카드(GPU) 메모리에 담기엔 너무나 큽니다. 이때 등장하는 구원투수가 바로 양자화(Quantization)입니다.
오늘은 AI 모델의 덩치를 줄이는 마법, 양자화가 무엇인지 그리고 어떤 방식들이 있는지 정리해 드립니다.
목차
1. AI 양자화 방식의 종류
- QAT (Quantization Aware Training): 모델을 학습하는 단계부터 4비트/8비트로 변환할 것을 고려하여 학습시키는 방식입니다. 성능은 가장 좋지만, 모델 전체를 처음부터 다시 학습해야 하므로 시간과 비용이 엄청나게 듭니다.
- NF4 (NormalFloat 4): 최근 QLoRA라는 미세조정(Fine-tuning) 기법에서 많이 쓰이는 방식입니다. 가중치가 정규 분포(Normal Distribution)를 따른다는 점을 수학적으로 이용하여, 4비트임에도 놀라운 성능 보존력을 보여줍니다.
- AQLM (Additive Quantization of Language Models): 아주 최근에 등장한 방식으로, 가중치를 여러 개의 룩업 테이블(Look-up Table) 조합으로 표현합니다. 2비트까지 압축해도 4비트 수준의 성능을 내는 혁신적인 기법입니다.
- SmoothQuant: 모델의 활성화 값(Activation)이 튀는 현상(Outlier)을 평탄화하여 양자화 오차를 줄이는 방식입니다. 연산 속도를 높이는 데 유리합니다.
2. 양자화 방식별 작업 난이도
작업 난이도는 크게 ‘도구 지원 정도’와 ‘연산 리소스’에 따라 갈립니다.
| 방식 | 작업 난이도 | 이유 |
| GGUF | 하 (매우 쉬움) | llama.cpp라는 강력한 도구가 변환을 자동화해 줍니다. 단점 표준화가 안된 AI는 난이도 상 |
| GPTQ | 중 (보통) | 라이브러리 간 버전 충돌(CUDA/PyTorch)이 잦으나, 자동화 툴이 많습니다. |
| AWQ | 중상 (까다로움) | 캘리브레이션 단계에서 연산 자원을 많이 먹고, 환경 설정이 까다롭습니다. |
| QAT | 최상 (매우 어려움) | 모델 학습을 다시 해야 하므로 연구실 수준의 자원이 필요합니다. |
3. AI 양자화 난이도가 결정되는 이유
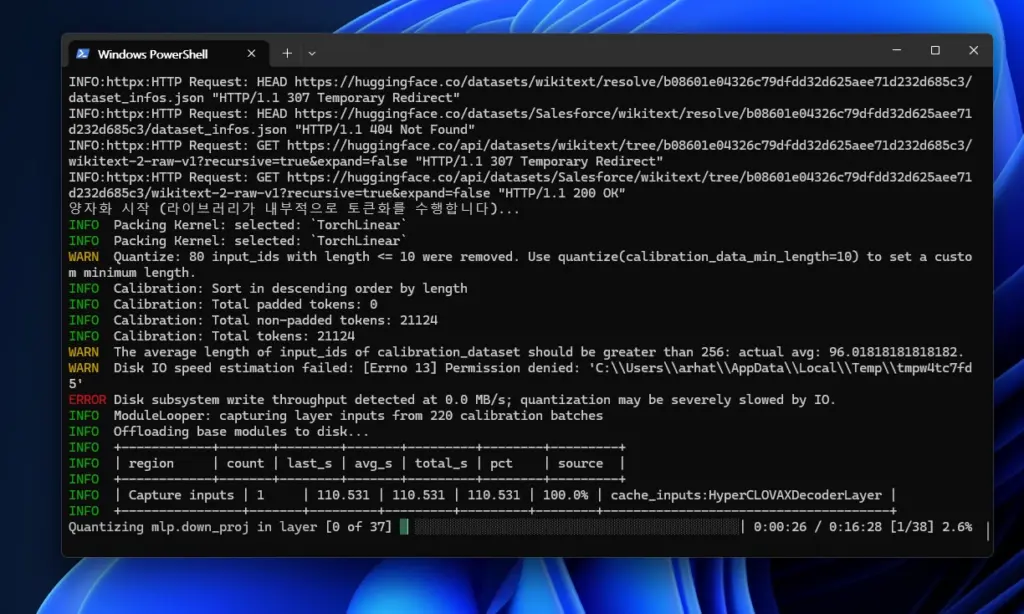
AI를 양자화 하면서 느끼시는 어려움은 단순히 “양자화가 어렵기 때문”이 아니라, “내 PC의 환경(윈도우 + 특정 모델 구조 + 라이브러리 버전)과 모델을 잇는 환경설정의 난이도” 때문입니다.
- 빌드 도구의 부재: 리눅스 기반으로 만들어진 AI 라이브러리들을 윈도우에서 돌리려니, 파이썬 패키지를 컴파일하는 C++ 컴파일러(Visual Studio Build Tools) 설정 등 부수적인 문제가 많이 발생합니다.
- 독자 구조: 하이퍼클로바X 같은 모델은 기존 라이브러리들의 ‘자동 경로’를 벗어나 있습니다. 이 때문에
Module Tree AutoCompat같은 우회로를 찾느라 고생하는 것입니다. - 메모리 제한: 14B 모델은 VRAM 8~12GB 정도로 아슬아슬하게 양자화가 가능한 규모입니다. 메모리가 넉넉하면 한 번에 끝날 일을, 메모리 부족으로 오프로딩(디스크 활용) 하려니 속도가 느려지고 에러 가능성이 커지는 것입니다.
4. 주요 양자화 방식 비교: GPTQ vs GGUF vs AWQ
현재 가장 많이 사용되는 양자화 방식 3가지를 비교해 보겠습니다.
| 구분 | GPTQ | GGUF (llama.cpp) | AWQ |
| 특징 | GPU 연산 최적화 중심 | CPU/GPU 하이브리드 최적화 | 성능 보존력 극대화 |
| 주요 목적 | 고성능 GPU 추론 | 개인 PC/맥 등 다양한 환경 | 정밀도 손실 최소화 |
| 장점 | 학습된 모델 변환이 빠름 | 단일 파일로 배포가 매우 간편함 | 4bit 양자화임에도 성능 저하가 거의 없음 |
| 단점 | 특정 GPU 사양에 민감함 | 변환 과정이 까다로움 | 변환 시 높은 컴퓨팅 자원 필요 |
GPTQ
주로 GPU 가속을 위해 설계되었으며, 모델의 레이어 구조를 해석하여 압축합니다. 학습된 모델의 가중치를 정교하게 보정하는 과정을 거쳐 성능을 유지합니다.
GGUF
llama.cpp와 한 몸처럼 움직이는 방식입니다. 파일을 하나로 합쳐서 배포하기 때문에, 복잡한 설치 과정 없이 모델 하나만 있으면 바로 실행할 수 있는 것이 가장 큰 장점입니다. 특히 VRAM이 부족한 환경에서 CPU를 활용해 추론을 가능하게 합니다.
AWQ (Activation-aware Weight Quantization)
최근 떠오르는 샛별입니다. 모델의 모든 가중치를 똑같이 압축하는 게 아니라, 모델의 판단에 중요한 ‘핵심 가중치’를 보호하면서 나머지 가중치를 압축합니다. 덕분에 4bit 양자화 모델 중에서 가장 원본 모델에 가까운 성능을 보여줍니다.
5. 왜 하이퍼클로바X는 GGUF로 안 될까?
많은 분이 궁금해하시는 점입니다. Llama나 Mistral 같은 모델들은 전 세계 누구나 사용하는 ‘공용 표준’ 구조를 가집니다. 그래서 llama.cpp 개발자들이 이미 해당 모델을 GGUF로 바꾸는 전용 번역기를 만들어 두었습니다.
반면, 하이퍼클로바X와 같은 독자 아키텍처는 그 구조가 비공개이거나 매우 독특합니다. GGUF로 바꾸려면 해당 모델만을 위한 전용 번역 코드를 밑바닥부터 새로 짜야 하는데, 이는 엄청난 전문성과 시간이 필요한 작업입니다. 반면 GPTQ는 모델의 내부 구조를 몰라도 ‘계산 노드(Linear 레이어)’만 찾아내어 강제로 압축하는 방식이라, 어떤 모델이든 범용적으로 적용할 수 있는 강력한 장점이 있습니다.
양자화는 단순히 모델을 작게 만드는 기술을 넘어, 누구나 자기만의 고성능 AI 모델을 로컬 환경에서 구동할 수 있게 해주는 방법입니다. 지금 고생하며 AI 양자화 과정이 성공한다면, 여러분은 14B 규모의 거대 모델을 여러분의 컴퓨터의 GPU 안에서 자유롭게 활용하실 수 있게 됩니다.