클라우드 API를 통해 AI 모델을 사용하는 방식은 편리하지만, 데이터 프라이버시, 비용, 인터넷 연결 의존성이라는 세 가지 근본적인 한계를 가집니다. 특히 기업 내부 문서, 개인 정보가 담긴 데이터를 처리해야 하는 경우에는 로컬 환경에서 AI 모델을 직접 구동하는 것이 유일한 선택지가 되기도 합니다.
네이버가 공개한 HyperCLOVAX-SEED-Think-14B는 140억 개의 파라미터를 가진 고성능 한국어 특화 대형 언어 모델입니다. 그러나 이 모델을 아무런 최적화 없이 로컬 PC에서 실행하려면 FP16(16비트 부동소수점) 기준으로 약 28GB 이상의 VRAM이 필요하며, 이는 일반 소비자용 GPU로는 사실상 불가능한 수준입니다.
이 문제를 해결하는 핵심 기술이 바로 네이버 AI 양자화(Quantization)입니다. 이번 글에서는 네이버 HyperCLOVAX 모델을 llama.cpp 기반의 GGUF 포맷으로 변환하고, Q4_K_M 방식으로 4비트 양자화를 적용하여 단 8~10GB의 VRAM으로 실행 가능한 상태로 만드는 전 과정을 진행 해봅니다.
목차
1부. 양자화의 원리와 HyperCLOVAX 적용 시 고려사항
1-1. AI 모델 양자화란 무엇인가
양자화(Quantization)란 모델의 가중치(Weight)를 표현하는 숫자의 정밀도(Precision)를 낮추는 기술입니다. 딥러닝 모델은 기본적으로 32비트(FP32) 또는 16비트(FP16) 부동소수점으로 가중치를 저장합니다. 이를 4비트 정수(INT4)나 8비트 정수(INT8)로 줄이면 모델 파일 크기와 메모리 사용량이 획기적으로 감소합니다.
수치로 알아보면 다음과 같습니다.
| 정밀도 | 비트 수 | HyperCLOVAX-14B 기준 용량 | VRAM 요구량 |
|---|---|---|---|
| FP32 | 32비트 | 약 56GB | 실행 불가 (소비자용 GPU) |
| FP16 | 16비트 | 약 28~30GB | A100급 전문 GPU 필요 |
| Q8_0 | 8비트 | 약 14~15GB | 24GB VRAM 필요 |
| Q4_K_M | 4비트 | 약 8~10GB | 12GB VRAM으로 실행 가능 |
Q4_K_M은 현재 llama.cpp 생태계에서 가장 널리 권장되는 양자화 방식으로, 4비트 양자화 중에서도 K-means 클러스터링 기법을 활용하여 성능 손실을 최소화하면서 압축률을 높일수 있습니다. “M”은 혼합(Mixed) 정밀도를 의미하며, 중요도가 높은 레이어에는 더 높은 비트 수를 배정하는 지능적인 방식입니다.
1-2. 텍스트 전용 모델과 HyperCLOVAX의 구조적 차이
일반적인 텍스트 전용 LLM(Large Language Model)은 Transformer 아키텍처를 기반으로 하며, llama.cpp의 표준 변환 스크립트가 직접 처리할 수 있도록 설계되어 있습니다. 예를 들어 LLaMA, Mistral, Qwen 같은 모델들은 별도 수정 없이도 convert_hf_to_gguf.py 스크립트가 잘 동작합니다.
그러나 HyperCLOVAX-SEED-Think-14B는 구조적으로 다릅니다. 이 모델은 다음과 같은 요소들을 포함하고 있기 때문입니다.
- 컨볼루션(Convolution) 레이어: 이미지나 멀티모달 처리를 위한 구조로, 표준 Transformer 변환기로 처리하기 어렵습니다.
- Squeeze-and-Excitation(SE) 블록: 채널 간 의존성을 학습하는 특수 구조로, 일반적인 양자화 엔진이 이 레이어를 인식하지 못하는 경우가 많습니다.
- 고유 텐서 명칭 체계: 표준 Llama 모델이
token_embd.weight,output_norm.weight등의 명칭을 사용하는 반면, HyperCLOVAX는 원본 훈련 코드의 명칭 규칙을 그대로 유지하여 호환성 문제를 일으킵니다.
이러한 이유로, 네이버 AI 와 특정 비전(Vision) 기능이 포함된 모델을 로컬에서 운용하려면 두 가지 접근법이 필요합니다.
- 텍스트 엔진 분리 최적화: 비전 컴포넌트를 제외한 텍스트 처리 엔진만을 분리하여 별도로 최적화
- 커스텀 매퍼(Custom Mapper) 구현: 모델의 고유 구조를 llama.cpp가 이해할 수 있는 형식으로 변환하는 커스텀 코드 작성
이번 방법에서는 두 번째 방식인 커스텀 매퍼를 활용한 GGUF 변환 및 양자화에 집중합니다.
2부. 사전 준비 — 환경 구성 및 저장 공간 확보
2-1. 하드웨어 요구 사항 점검
네이버 AI를 양자화 하기 위해서는 반드시 아래 요구 사항을 확인하세요.
컴퓨터 AI 저장 공간
- HyperCLOVAX-SEED-Think-14B 원본 모델(FP16): 약 28GB 이상
- 변환 과정 중 생성되는 임시 파일: 추가 20~30GB
- 최종 Q4_K_M 양자화 파일: 약 8~10GB
⚠️ 최소 60GB 이상의 여유 저장 공간이 반드시 필요합니다. SSD 사용을 강력히 권장하며, HDD 사용 시 변환 시간이 수 시간 이상 소요될 수 있습니다.
GPU VRAM
- Q4_K_M 실행 기준: 12GB VRAM 이상 권장
- 대표 호환 GPU: NVIDIA RTX 3080 (10GB)는 다소 부족, RTX 3080 Ti / 4070 Ti (12GB) 이상이 적합
RAM
- 변환 작업 중 모델을 RAM에 올려야 하므로 최소 32GB RAM 권장 (64GB 이상이면 더욱 안정적)
2-2. llama.cpp 환경 설정
네이버 HyperCLOVAX 모델의 양자화를 위해 가장 먼저 llama.cpp를 로컬에 설치해야 합니다. llama.cpp는 C++로 작성된 오픈소스 LLM 추론 엔진으로, GGUF 형식의 모델을 CPU 및 GPU에서 빠르게 실행할 수 있게 해줍니다.
HyperCLOVAX와 같은 신형 모델의 구조를 지원하려면 반드시 최신 버전을 사용해야 합니다. 오래된 버전의 llama.cpp는 새로운 모델 아키텍처나 토크나이저 형식을 인식하지 못할 수 있습니다.
# llama.cpp 최신 버전 클론
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
# 파이썬 의존성 패키지 설치
pip install -r requirements.txt위 명령어 실행 후 requirements.txt에 명시된 패키지들이 모두 설치됩니다. 이 패키지들에는 numpy, sentencepiece, transformers, gguf 등 변환에 필수적인 라이브러리가 포함되어 있습니다.
2-3. llama.cpp 빌드 (llama-quantize.exe 생성)
양자화 작업에 필요한 핵심 실행 파일인 llama-quantize.exe(Windows) 또는 llama-quantize(Linux/macOS)를 생성하려면 llama.cpp를 컴파일해야 합니다.
Windows(CMake 사용):
cmake -B build
cmake --build build --config Release컴파일이 완료되면 build/bin/Release/ 폴더 내에 실행 파일들이 생성됩니다. 양자화에 필요한 핵심 파일들의 위치를 정리하면 다음과 같습니다.
- 모델 변환 스크립트:
G:\naver_ai\convert_hf_to_gguf.py - 양자화 도구:
G:\naver_ai\llama-quantize.exe
3부. 네이버 AI 모델 다운로드
3-1. huggingface_hub 설치
네이버 HyperCLOVAX 모델은 Hugging Face Hub에 공개되어 있습니다. 이를 터미널에서 직접 다운로드하는 가장 효율적인 방법은 huggingface_hub 라이브러리의 hf CLI 명령어를 활용하는 것입니다.
먼저 아래 명령어로 패키지를 설치하세요:
pip install -U huggingface_hub-U 옵션은 기존에 설치된 버전이 있더라도 최신 버전으로 업그레이드합니다. 구버전의 huggingface_hub에는 대용량 파일 처리 시 불안정한 문제가 있으므로 반드시 최신 버전을 유지하세요.
3-2. 모델 다운로드 명령어 실행
특정 폴더에 모델을 직접 저장하려면 --local-dir 옵션을 사용하는 것이 권장됩니다. 아래 명령어를 원하는 경로에 맞게 수정하여 실행하세요.
hf download naver-hyperclovax/HyperCLOVAX-SEED-Think-14B \
--local-dir ./HyperCLOVAX-SEED-Think-14B각 옵션의 의미는 다음과 같습니다.
naver-hyperclovax/HyperCLOVAX-SEED-Think-14B: Hugging Face의 모델 리포지토리 ID입니다.[사용자명]/[모델명]형식을 따릅니다.--local-dir: 다운로드할 로컬 경로를 지정합니다. 위 명령어는 현재 실행 위치의HyperCLOVAX-SEED-Think-14B디렉토리에 파일을 저장합니다.
알아두면 좋은 사항들
| 항목 | 내용 |
|---|---|
| 캐시 기본 경로 | --local-dir 미지정 시 ~/.cache/huggingface/hub에 저장 |
| Windows 심볼릭 링크 | 관리자 권한 실행 또는 개발자 모드 활성화 필요 |
| 대용량 파일 처리 | git lfs 기반 동작으로 수십 GB 모델도 안정적 다운로드 가능 |
| 다운로드 재개 | 연결 중단 시 동일 명령어 재실행하면 중단점부터 재개 |
4부. 모델 구조 사전 분석 — 텐서 이름 추출 도구
4-1. GGUF 변환 전 텐서 이름 확인이 중요한 이유
llama.cpp가 GGUF 파일을 읽을 때, 내부적으로 특정 이름을 가진 텐서들이 반드시 존재해야 합니다. 예를 들어 token_embd.weight(임베딩 레이어), output_norm.weight(출력 정규화 레이어)가 없으면 missing tensor 오류가 발생하며 모델 로딩이 실패합니다.
문제는 네이버 HyperCLOVAX 모델이 이 텐서들을 다른 이름으로 저장하고 있다는 점입니다. 원본 훈련 코드의 명칭 규칙을 그대로 따르기 때문에, 변환 작업 전에 어떤 이름들이 실제로 존재하는지를 먼저 파악해야 합니다.
4-2. safetensors 텐서 이름 추출 스크립트
아래 Python 스크립트는 safetensors 형식의 모델 파일들을 탐색하여 내부에 저장된 모든 텐서 이름을 텍스트 파일로 추출합니다.
import torch
from safetensors.torch import load_file
import os
# 모델이 저장된 경로 (실제 경로로 변경하세요)
model_path = r"G:\AI_Study\Ai_model\HyperCLOVAX-SEED-Think-14B"
# 텐서 이름 목록을 저장할 경로
save_path = r'G:\naver_ai'
# safetensors 파일 목록 수집
files = [f for f in os.listdir(model_path) if f.endswith('.safetensors')]
if not files:
print(f"경로를 확인해주세요: {model_path} 에 safetensors 파일이 없습니다.")
else:
output_file = os.path.join(save_path, 'tensor_names.txt')
with open(output_file, 'w', encoding='utf-8') as f:
for file in files:
print(f"Reading {file}...")
f.write(f"--- File: {file} ---\n")
# safetensors 파일 로드 및 키 추출
weights = load_file(os.path.join(model_path, file))
for name in weights.keys():
f.write(name + '\n')
print(f"완료! {output_file} 파일이 생성되었습니다.")스크립트 동작 방식
- 파일 탐색: 지정된 경로에서
.safetensors확장자를 가진 파일들을 모두 찾아냅니다. - 가중치 추출: 각 파일을 하나씩 불러와 내부적으로 저장된 모든 키(텐서 이름)를 순회합니다.
- 텍스트 저장: 추출된 텐서 이름들을
tensor_names.txt파일에 기록합니다.
터미널에서 직접 실행하는 방법:
python check_tensors_G.py "G:\AI_Study\Ai_model\HyperCLOVAX-SEED-Think-14B" > tensor_list.txt생성된 tensor_names.txt 파일에서 norm, embed, embd 등의 키워드로 검색하면 llama.cpp가 요구하는 표준 텐서명과의 차이점을 빠르게 파악할 수 있습니다.
5부. GGUF 포맷 변환 — convert_hf_to_gguf.py 커스터마이징
5-1. HyperCLOVAX 텐서 이름 문제의 핵심
convert_hf_to_gguf.py는 llama.cpp가 제공하는 공식 변환 스크립트입니다. 이 스크립트는 Hugging Face 형식(.safetensors)의 모델을 GGUF 형식으로 변환합니다. 그런데 HyperCLOVAX와 같은 비표준 모델을 변환할 때는 다음과 같은 텐서 명칭 불일치 문제가 발생합니다.
| 원본 모델 내 실제 텐서명 | llama.cpp가 요구하는 표준명 |
|---|---|
model.embed_tokens.weight | token_embd.weight |
model.norm.weight | output_norm.weight |
norm.weight | output_norm.weight |
model.final_norm.weight | output_norm.weight |
이 불일치를 해결하지 않으면 변환 후 missing tensor 'output_norm.weight' 또는 missing tensor 'token_embd.weight' 오류가 발생하며 모델 실행이 불가능합니다.
5-2. write_tensors 함수 직접 수정 방법
convert_hf_to_gguf.py 파일 전체에서 def write_tensors(self):를 검색합니다. 해당 함수의 for 루프를 아래와 같이 교체하세요.
def write_tensors(self):
for name, data_torch in self.get_tensors():
# [핵심 수정] 텐서 이름 강제 변환
if name == "model.embed_tokens.weight":
name = "token_embd.weight"
self.gguf_writer.add_tensor(name, data_torch.numpy())이 방식의 장점은 파일 기록(add_tensor) 바로 직전에 이름을 변환한다는 것입니다. 이전에 다른 위치에서 이름을 바꿨더라도 변환기의 다른 로직이 원래 이름으로 복원할 가능성이 있었지만, 이 위치에서 변경하면 그 틈이 완전히 차단됩니다.
get_tensors()는 safetensors 파일에서 텐서를 읽어오는 함수이며, write_tensors()는 그 텐서를 실제 .gguf 파일에 기록하는 함수입니다. 두 단계 중 기록 직전인 write_tensors() 내부에서 이름을 바꾸는 것이 가장 확실한 방법입니다.
5-3. 전역 패치 방식 — 텐서 이름 자동 변환기 적용
더 포괄적인 해결책으로, convert_hf_to_gguf.py 파일의 가장 하단, 클래스 정의가 끝난 맨 마지막 줄에 아래 코드를 추가할 수 있습니다. 이 코드는 GGUF 라이브러리 내부의 add_tensor 함수를 가로채어(monkey-patching) 강제로 이름을 변환합니다.
# 기존 패치 코드 전체를 지우고 아래 내용으로 교체하세요
def patched_add_tensor(self, name, tensor, *args, **kwargs):
# 매핑 테이블: 원본 이름 -> llama.cpp 표준 이름
mapping = {
"model.embed_tokens.weight": "token_embd.weight",
"model.norm.weight": "output_norm.weight",
"model.norm": "output_norm.weight",
"norm.weight": "output_norm.weight",
}
# 이름 변환 수행
if name in mapping:
name = mapping[name]
return self.original_add_tensor(name, tensor, *args, **kwargs)
import gguf
if not hasattr(gguf.GGUFWriter, 'original_add_tensor'):
gguf.GGUFWriter.original_add_tensor = gguf.GGUFWriter.add_tensor
gguf.GGUFWriter.add_tensor = patched_add_tensor
if __name__ == "__main__":
main()이 패치의 동작 원리는 다음과 같습니다.
- 원본
add_tensor함수를original_add_tensor로 보관합니다. - 새로 정의한
patched_add_tensor가add_tensor자리를 대신합니다. - 모든 텐서가 저장될 때마다 매핑 테이블을 확인하여 이름을 자동으로 변환합니다.
- 이름 변환 후 원본 함수를 호출하여 실제 저장 작업을 수행합니다.
이 방식을 사용하면 매핑 테이블에 항목을 추가하는 것만으로도 새로운 텐서 명칭 문제를 유연하게 해결할 수 있습니다.
! 네이버 AI 양자화 오류 해결팁 1
trust_remote_code 문제를 해결하려면 convert_hf_to_gguf.py코드에서 trust_remote_code=False 부분을 True로 바꾸는 것이 핵심입니다. 아래에 load_hparams 함수 전체 수정본입니다.
이 코드를 convert_hf_to_gguf.py 파일 내에 있는 기존 load_hparams 함수와 완전히 교체하십시오.
def load_hparams(dir_model: Path, is_mistral_format: bool):
if is_mistral_format:
with open(dir_model / "params.json", "r", encoding="utf-8") as f:
config = json.load(f)
return config
try:
# HyperCLOVAX의 커스텀 코드를 실행하기 위해 trust_remote_code를 True로 설정
config = AutoConfig.from_pretrained(
dir_model, trust_remote_code=True
).to_dict()
except Exception as e:
logger.warning(f"Failed to load model config from {dir_model}: {e}")
logger.warning("Trying to load config.json instead")
with open(dir_model / "config.json", "r", encoding="utf-8") as f:
config = json.load(f)
if "architectures" in config and config["architectures"] and "HyperCLOVAX" in config["architectures"][0]:
print("HyperCLOVAX detected, overriding architecture to LlamaForCausalLM")
config["architectures"] = ["LlamaForCausalLM"]
if "llm_config" in config:
config["text_config"] = config["llm_config"]
if "lm_config" in config:
config["text_config"] = config["lm_config"]
if "thinker_config" in config:
config["text_config"] = config["thinker_config"]["text_config"]
if "language_config" in config:
config["text_config"] = config["language_config"]
if "lfm" in config:
config["text_config"] = config["lfm"]
return config! 네이버 AI 양자화 오류 해결팁 2
missing tensor 'output_norm.weight' 오류만 해결하기 이 오류가 발생하는 이유는, 변환기(convert_hf_to_gguf.py)가 HyperCLOVAX 모델의 출력층 정규화 텐서 이름을 llama.cpp가 이해하는 이름으로 바꾸지 못했기 때문입니다.
def patched_add_tensor(self, name, tensor, *args, **kwargs):
# 매핑 테이블: 원본 모델 이름 -> llama.cpp 필수 이름
mapping = {
"model.embed_tokens.weight": "token_embd.weight",
"model.norm.weight": "output_norm.weight",
"norm.weight": "output_norm.weight",
"model.final_norm.weight": "output_norm.weight",
"final_norm.weight": "output_norm.weight",
"output_norm.weight": "output_norm.weight" # 이미 있다면 유지
}
# 텐서 이름 강제 치환
if name in mapping:
name = mapping[name]
return self.original_add_tensor(name, tensor, *args, **kwargs)6부. GGUF 변환 실행 및 4비트 양자화 수행
6-1. GGUF 변환 전 파이썬 캐시 삭제 (필수)
코드 수정 후 변환을 다시 실행하기 전에 반드시 Python 컴파일 캐시를 삭제해야 합니다. Python은 이전에 컴파일된 .pyc 파일을 수정한 .py 파일보다 우선적으로 읽는 경우가 있어, 코드를 수정했음에도 불구하고 이전 동작이 반복될 수 있습니다.
PowerShell에서 아래 명령어를 실행하세요:
Get-ChildItem -Path . -Recurse -Filter "__pycache__" -Directory | Remove-Item -Recurse -Force또한 이전 변환 시 생성된 오류가 있는 .gguf 파일이 있다면 반드시 삭제하세요. 잘못된 기존 파일이 남아있으면 새로 실행해도 동일한 오류가 계속 발생합니다.
# 기존 오류 파일 삭제 예시
Remove-Item "G:\AI_Study\Ai_model\HyperCLOVAX-Fixed-Final.gguf"💡 파일이 다른 프로그램에서 사용 중이라는 메시지가 나오면, 터미널을 닫았다가 다시 열거나 작업 관리자에서
llama-cli.exe프로세스를 종료한 후 삭제하세요.
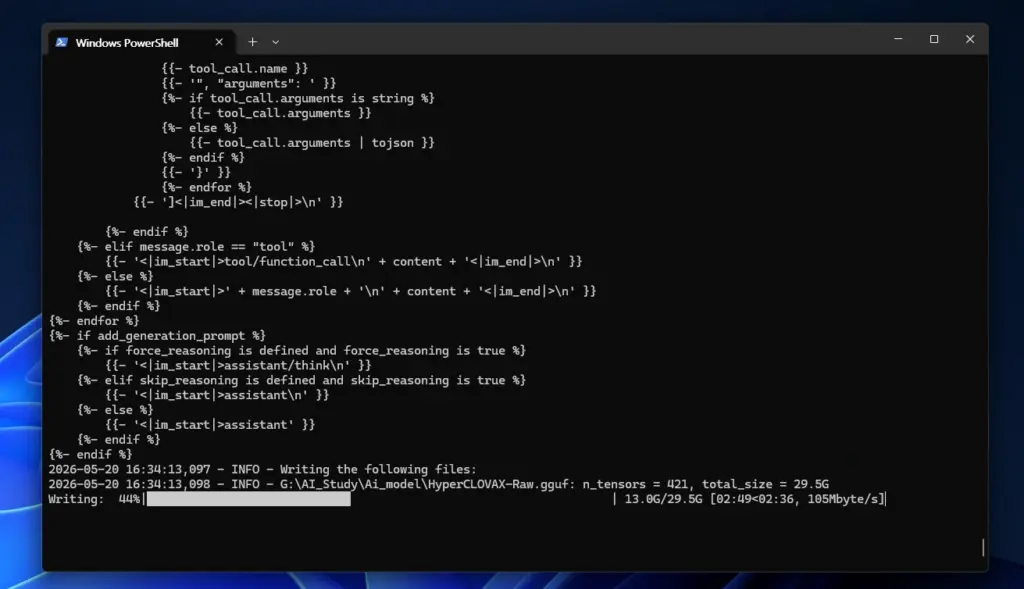
6-2. FP16 GGUF 변환 실행
모든 준비가 완료되었다면 아래 명령어로 HyperCLOVAX 모델을 FP16 정밀도의 GGUF 파일로 변환합니다.
python convert_hf_to_gguf.py "G:\AI_Study\Ai_model\HyperCLOVAX-SEED-Think-14B" --outtype f16- 입력:
G:\AI_Study\Ai_model\HyperCLOVAX-SEED-Think-14B— 모델 파일들이 있는 디렉토리 --outtype f16: 출력 파일의 정밀도를 FP16으로 지정- 출력:
HyperCLOVAX-Raw.gguf(약 28~30GB) — 이 파일이 양자화의 입력이 됩니다
변환 중 터미널에 출력되는 텐서 이름 목록을 주의 깊게 관찰하세요. 앞서 삽입한 패치 코드가 제대로 동작한다면 "model.embed_tokens.weight" → "token_embd.weight" 형태의 변환 로그를 확인할 수 있습니다.
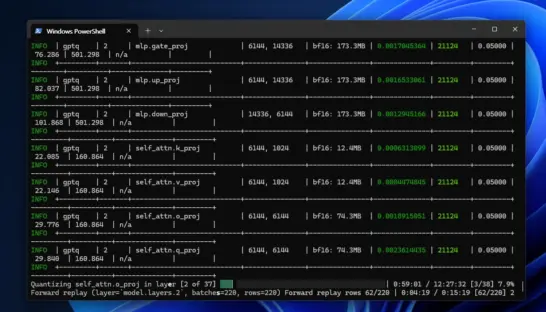
6-3. Q4_K_M 4비트 양자화 실행
FP16 GGUF 파일 생성이 완료되면, 이 파일을 입력으로 받아 4비트 양자화를 수행합니다.
.\llama-quantize.exe `
"G:\AI_Study\Ai_model\HyperCLOVAX-Raw.gguf" `
"G:\AI_Study\Ai_model\HyperCLOVAX-Q4_K_M.gguf" `
Q4_K_M각 인수의 의미:
- 첫 번째 경로: 입력 파일 (FP16 GGUF, 약 28~30GB)
- 두 번째 경로: 출력 파일 (Q4_K_M 양자화 GGUF, 약 8~10GB)
Q4_K_M: 양자화 방식 지정
양자화 과정은 CPU에서 수행되며, 시스템 성능에 따라 수십 분에서 수 시간이 소요될 수 있습니다. 완료 시 HyperCLOVAX-Q4_K_M.gguf 파일이 생성되며, 용량이 8~10GB 수준으로 줄어든 것을 확인할 수 있습니다.
압축 전후 비교:
| 파일명 | 정밀도 | 용량 | 12GB VRAM 실행 가능 여부 |
|---|---|---|---|
| HyperCLOVAX-Raw.gguf | FP16 | ~30GB | 불가 |
| HyperCLOVAX-Q4_K_M.gguf | 4bit | ~9GB | 가능 |
7부. 모델 로딩 및 실행
7-1. llama-cli를 이용한 GPU 로딩
양자화된 모델을 12GB VRAM GPU에서 실행하려면 아래 명령어를 사용합니다.
.\llama-cli.exe `
-m "G:\AI_Study\Ai_model\HyperCLOVAX-Q4_K_M.gguf" `
-p "안녕하세요." `
-n 128 `
--color on `
-ngl 99주요 옵션 설명:
| 옵션 | 설명 |
|---|---|
-m | 모델 파일 경로 |
-p | 프롬프트 (입력 텍스트) |
-n 128 | 생성할 최대 토큰 수 |
--color on | 터미널 컬러 출력 활성화 |
-ngl 99 | GPU에 올릴 레이어 수 (99는 “최대한 많이”를 의미) |
-ngl 옵션 튜닝 가이드
-ngl은 “number of GPU layers”의 약자로, 모델 레이어 중 몇 개를 GPU VRAM에 올릴지를 결정합니다. VRAM이 충분하다면 -ngl 99로 전체 레이어를 GPU에 올리는 것이 가장 빠릅니다. VRAM이 부족할 경우 일부 레이어가 RAM으로 내려오며 속도가 느려질 수 있습니다.
- 12GB VRAM + Q4_K_M(~9GB) 조합:
-ngl 99설정 시 대부분의 레이어가 VRAM에 올라가고 나머지 VRAM(약 3GB)으로 컨텍스트(대화 기록)를 처리할 수 있어 매우 빠른 추론 속도를 기대할 수 있습니다.
8부. 변환 오류 진단 및 해결 — 심화 디버깅 방법
8-1. missing tensor 오류의 원인과 구조적 이해
missing tensor 'output_norm.weight' 또는 missing tensor 'token_embd.weight' 오류는 가장 흔하게 발생하는 문제입니다. 이 오류가 계속 발생하는 근본 원인은 convert_hf_to_gguf.py가 모델을 읽을 때, 특정 텐서들을 llama.cpp가 요구하는 표준 명칭이 아닌 원본 모델의 고유 이름으로 변환하고 있기 때문입니다.
예를 들어 output_norm.weight가 없다는 오류는 원본 모델에서 해당 텐서가 model.final_norm.weight, norm.weight, 또는 다른 이름으로 저장되어 있기 때문입니다. 매핑 테이블에서 이 이름을 누락했다면 변환 후에도 오류가 계속됩니다.
8-2. 로그 기반 텐서 이름 자동 진단 시스템 구축
가장 효과적인 디버깅 방법은 변환 과정에서 처리되는 모든 텐서 이름을 로그 파일에 기록하는 것입니다. convert_hf_to_gguf.py 하단에 기존 패치 코드 대신 아래 코드를 삽입하세요.
import logging
import sys
# 로그 설정: 터미널과 파일에 동시 기록
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler("conversion_debug.log", mode='w', encoding='utf-8'),
logging.StreamHandler(sys.stdout)
]
)
logger = logging.getLogger(__name__)
# 1. 패치 함수 정의
def patched_add_tensor(self, name, tensor, *args, **kwargs):
# 매핑 테이블
mapping = {
"model.embed_tokens.weight": "token_embd.weight",
"model.norm.weight": "output_norm.weight",
"norm.weight": "output_norm.weight",
"model.final_norm.weight": "output_norm.weight",
"final_norm.weight": "output_norm.weight",
"output_norm.weight": "output_norm.weight",
}
new_name = name
# 동적 레이어 변환 (attention_norm -> attn_norm 으로 수정)
if name.startswith("model.layers."):
parts = name.split(".")
idx = parts[2]
if "input_layernorm" in name:
new_name = f"blk.{idx}.attn_norm.weight" # 수정 완료
elif "post_attention_layernorm" in name:
new_name = f"blk.{idx}.ffn_norm.weight"
elif "self_attn.q_proj" in name:
new_name = f"blk.{idx}.attn_q.weight"
elif "self_attn.k_proj" in name:
new_name = f"blk.{idx}.attn_k.weight"
elif "self_attn.v_proj" in name:
new_name = f"blk.{idx}.attn_v.weight"
elif "self_attn.o_proj" in name:
new_name = f"blk.{idx}.attn_output.weight"
elif "mlp.gate_proj" in name:
new_name = f"blk.{idx}.ffn_gate.weight"
elif "mlp.up_proj" in name:
new_name = f"blk.{idx}.ffn_up.weight"
elif "mlp.down_proj" in name:
new_name = f"blk.{idx}.ffn_down.weight"
if name in mapping:
new_name = mapping[name]
if name != new_name:
logger.info(f"DEBUG: Mapping '{name}' -> '{new_name}'")
return self.original_add_tensor(new_name, tensor, *args, **kwargs)
# 2. 몽키 패치 적용
if not hasattr(gguf.GGUFWriter, 'original_add_tensor'):
gguf.GGUFWriter.original_add_tensor = gguf.GGUFWriter.add_tensor
gguf.GGUFWriter.add_tensor = patched_add_tensor8-3. 로그 파일 활용 절차
위 코드를 삽입하고 변환을 실행하면 conversion_debug.log 파일이 생성됩니다. 이를 활용하는 절차는 다음과 같습니다.
Step 1. 변환 실행
python convert_hf_to_gguf.py "G:\AI_Study\Ai_model\HyperCLOVAX-SEED-Think-14B" --outtype f16Step 2. 로그 파일 열기
변환 완료 후 conversion_debug.log 파일을 텍스트 에디터로 엽니다.
Step 3. 오류 원인 찾기
로그 파일에서 WARNING 키워드로 검색합니다. Potential Mismatch detected: '[텐서명]' 형태의 경고가 나타난다면, 그 텐서명이 바로 매핑 테이블에 추가해야 할 대상입니다.
Step 4. 매핑 추가
확인된 텐서명을 mapping 딕셔너리에 추가합니다:
mapping = {
...
"발견된_실제_텐서명": "llama.cpp_표준_텐서명",
}Step 5. 캐시 삭제 후 재실행
앞서 설명한 파이썬 캐시 삭제 명령어를 실행한 뒤 변환을 다시 수행합니다.
9부. 자주 발생하는 문제와 해결책 총정리
변환 중 “safetensors 파일을 찾을 수 없음” 오류
모델 경로가 잘못 지정되었거나, 다운로드가 완전히 완료되지 않았을 가능성이 있습니다.
1. os.listdir(model_path)로 실제 파일 목록을 확인
2. Hugging Face 다운로드를 재실행하여 파일 무결성 확인
3. 경로에 한글이나 특수문자가 포함되어 있다면 영문 경로로 변경
변환 후에도 계속 missing tensor 오류 발생
원인: 수정한 코드가 반영되지 않았거나, 매핑 테이블에 해당 텐서명이 누락된 경우입니다1. __pycache__ 폴더 완전 삭제 (캐시 무효화)
2. 이전 .gguf 파일 삭제 후 재변환
3. 로그 파일로 실제 텐서명 확인 후 매핑 추가
양자화 도구(llama-quantize.exe)를 찾을 수 없음
원인: llama.cpp 컴파일이 완료되지 않았거나, 빌드 경로가 다를 수 있습니다.
1. cmake --build build --config Release 명령어로 재컴파일2. build/bin/Release/ 폴더에서 실행 파일 확인
3. Windows Defender가 실행 파일을 격리시켰을 가능성 확인
12GB VRAM에서 모델 로딩 실패 (VRAM 부족)
원인: Q4_K_M 모델(~9GB)에 컨텍스트 처리 메모리까지 더하면 12GB를 초과할 수 있습니다.
1. -ngl 값을 99 → 40~50으로 줄여 일부 레이어를 RAM으로 이동
2. 컨텍스트 길이(-c 옵션) 를 줄여 메모리 사용량 감소
3. 더 강한 압축의 Q3_K_M 또는 Q2_K 양자화 방식 시도
10부. 전체 작업 흐름 요약
아래는 처음부터 끝까지의 전체 작업 순서를 한눈에 정리한 것입니다.
[1단계] 환경 준비
├── llama.cpp 최신 버전 클론 및 빌드
└── huggingface_hub 설치 (pip install -U huggingface_hub)
[2단계] 모델 다운로드
└── hf download naver-hyperclovax/HyperCLOVAX-SEED-Think-14B --local-dir ./...
[3단계] 텐서 이름 사전 분석 (선택 사항이지만 강력 권장)
└── check_tensors_G.py 실행 → tensor_names.txt 생성 → norm/embd 관련 이름 확인
[4단계] convert_hf_to_gguf.py 커스터마이징
├── write_tensors() 함수 내 이름 변환 코드 추가
└── 전역 패치(patched_add_tensor) 및 로그 시스템 삽입
[5단계] 파이썬 캐시 삭제
└── Get-ChildItem -Path . -Recurse -Filter "__pycache__" -Directory | Remove-Item -Recurse -Force
[6단계] GGUF 변환 (FP16)
└── python convert_hf_to_gguf.py [모델경로] --outtype f16
→ HyperCLOVAX-Raw.gguf 생성 (약 30GB)
[7단계] 4비트 양자화
└── llama-quantize.exe [입력.gguf] [출력.gguf] Q4_K_M
→ HyperCLOVAX-Q4_K_M.gguf 생성 (약 8~10GB)
[8단계] 모델 실행 테스트
└── llama-cli.exe -m [모델경로] -p "안녕하세요." -n 128 -ngl 99네이버 HyperCLOVAX-SEED-Think-14B의 로컬 실행은 단순한 기술적 도전을 넘어, 한국어 특화 AI를 완전히 내 손 안에서 구동할 수 있다는 의미를 가집니다. 클라우드 서비스에 의존하지 않고, 인터넷이 없는 환경에서도, 내 데이터를 외부로 내보내지 않고도 강력한 한국어 AI를 활용할 수 있게 됩니다.
이번 글에서 다룬 핵심 방법들을 정리하면:
- llama.cpp GGUF 변환: 다양한 아키텍처의 모델을 통합된 포맷으로 변환하는 표준 도구
- Q4_K_M 4비트 양자화: 성능 손실 최소화와 메모리 효율 극대화의 최적 균형점
- 커스텀 매퍼(텐서 이름 패치): 비표준 모델 구조를 처리하는 핵심 기술
- 로그 기반 디버깅: 텐서 명칭 불일치 문제를 체계적으로 해결하는 방법론
향후 Transformers 라이브러리 연동, llama.cpp 서버 모드 활용, Open WebUI를 통한 ChatGPT 스타일 인터페이스 구축 등 더 다양한 확장 활용 방법도 탐구해 볼 수 있습니다.
참고자료
가상환경 활성화 & ".\venv\Scripts\Activate.ps1" gguf 변환 명령어
python AUTO_convert_naver_to_gguf.py “G:\AI_Study\Ai_model\HyperCLOVAX-SEED-Think-14B” –outfile “G:\AI_Study\Ai_model\HyperCLOVAX-FP16.gguf” –outtype f16 –verbose
양자화 코드
.\llama-quantize.exe "G:\AI_Study\Ai_model\HyperCLOVAX-FP16.gguf" "G:\AI_Study\Ai_model\HyperCLOVAX-Q4_K_M.gguf" q4_k_m