티스토리 블로그 데이터 기반 AI RAG 구현 방법.AI가 못 찾는 문제 해결! 의미 검색과 키워드 검색을 결합한 하이브리드 RAG 설계및 의미 검색과 키워드 검색 병합으로 ‘자료 없음’ 문제를 극복하는 방법 소개.
최근 챗GPT나 제미나이(Gemini) 같은 LLM을 활용해 내 블로그의 데이터를 학습시키고 답변하는 RAG(Retrieval-Augmented Generation, 검색 증강 생성) 시스템을 구축하는 분들이 많아졌습니다. 저 또한 티스토리 블로그 데이터를 기반으로 나만의 AI 어시스턴트를 구축해 운영 중입니다.
하지만 시스템을 구축하다 보면 누구나 반드시 한 번쯤은 이런 당혹스러운 상황을 겪게 됩니다.
분명 내 블로그에 밤요리 레시피 글이 있는데, AI는 왜 자료가 없다고 할까?
AI 쇼츠 제작, 다다미 방, 온돌의 우수성처럼 블로그에 명확한 단어와 포스팅이 존재함에도 불구하고, AI는 계속해서 제공된 자료에서 관련 내용을 찾을 수 없습니다라는 답변만 반복합니다.
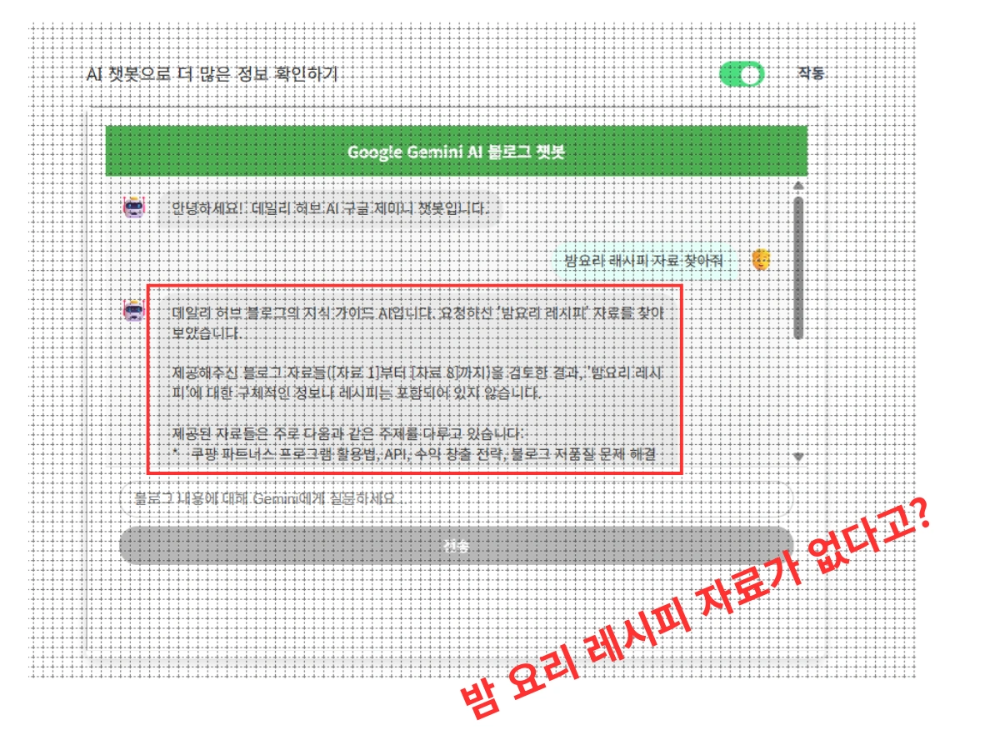
이 문제는 여러분의 데이터가 부족해서도, 제미나이 모델의 성능이 떨어져서도 아닙니다. 원인은 바로 검색 구조 자체의 결함에 있습니다. 오늘은 제가 직접 겪은 시행착오를 바탕으로, AI가 멍청해지는 이유와 이를 해결하는 ‘하이브리드 검색’ 설계법을 정리해 드립니다.
1. 기존 RAG 구조의 치명적인 한계: 왜 ‘의미’만 찾을까?
대부분의 입문용 RAG 가이드는 다음과 같은 표준 흐름을 따릅니다.
- 질문 수신: 사용자가 “밤요리 레시피 알려줘”라고 질문함.
- 임베딩 생성: 질문을 숫자 배열(Vector)로 변환.
- 벡터 DB 조회: Pinecone 같은 벡터 DB에서 유사도가 높은 자료를 검색.
- 답변 생성: 검색된 결과가 없으면 “자료 없음” 출력.
이 방식은 이론적으로는 완벽해 보이지만, 실제 블로그 검색 환경에서는 치명적인 약점을 가집니다.
원인 1: Pinecone은 전통적인 검색엔진이 아닙니다
우리가 흔히 쓰는 구글이나 네이버 검색은 ‘단어’를 찾습니다. 하지만 Pinecone 같은 벡터 DB는 문자열 검색 기능이 없습니다. 오로지 의미적으로 얼마나 유사한가라는 기하학적 거리만 계산합니다.
문제는 “밤요리”처럼 단어 자체가 짧고 고유한 명사인 경우, 임베딩 모델이 이 단어의 ‘의미’를 “밤(Night)”으로 해석하거나 전혀 엉뚱한 기술적 맥락과 연결할 가능성이 크다는 것입니다. 결과적으로 유사도 점수가 낮게 측정되어 검색 결과에서 누락됩니다.
원인 2: 사용자는 ‘의미’보다 ‘단어’를 던집니다
블로그 방문자의 검색 패턴을 분석해 보면, 사람들은 문장으로 길게 설명하기보다 핵심 키워드를 던지는 경향이 강합니다.
- 사용자 의도: “제목에 ‘밤요리’가 들어간 글을 찾아줘.”
- AI 검색 방식: “밤요리와 유사한 철학적 의미를 지닌 문서를 뒤져보자.”
이 간극이 커질수록 AI는 자료를 눈앞에 두고도 못 찾는 ‘장님’ 상태가 됩니다.
2. 해결 방법: 의미(Semantic) + 키워드(Keyword) 하이브리드 설계
이 문제를 해결하기 위해 제가 도입한 방식은 ‘하이브리드 검색(Hybrid Search)’입니다. 뇌가 왼쪽과 오른쪽을 모두 쓰듯, AI에게도 두 가지 검색 경로를 동시에 열어주는 것입니다.
최종 하이브리드 검색 구조
- 사용자 질문 유입
- Route A (의미 검색): 질문을 벡터로 변환하여 Pinecone에서 유사 문맥 탐색. (맥락 파악용)
- Route B (고감도 키워드 검색): 질문 속 단어를 토큰화하여 DB 전체 메타데이터에서 직접 매칭. (정확도 확보용)
- 결과 병합: 두 경로에서 얻은 자료를 하나로 합치고 중복 제거.
- AI 답변 생성: 풍부해진 문맥을 바탕으로 Gemini가 최종 답변.
3. 핵심 기술 구현 포인트 (Google Apps Script 기반)
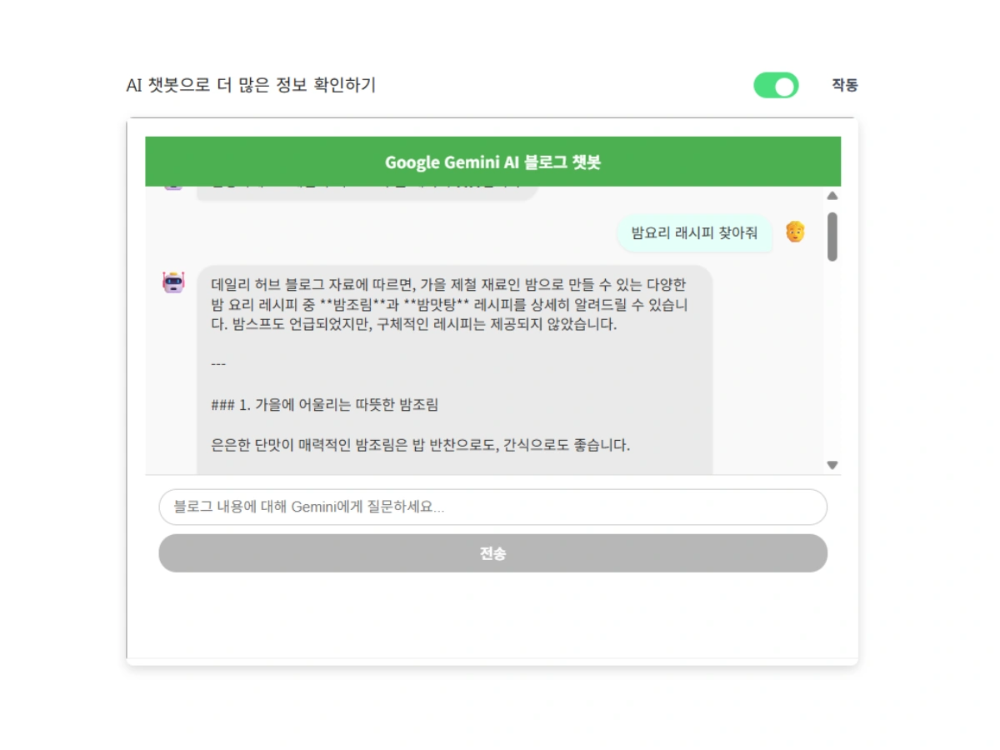
실제로 제가 적용하여 “밤요리 레시피” 검색 문제를 해결한 핵심 로직 3가지를 공개합니다.
핵심 1: 고감도 키워드 스코어링 도입
의미 검색이 놓치는 단어를 잡기 위해, 전체 후보군을 대상으로 직접적인 문자열 검사를 수행합니다.
- 토큰화: “밤요리 레시피”를 [밤, 요리, 레시피]로 분해합니다.
- 가중치 부여: 문서 제목에 단어가 포함되면 +5점, 본문에 포함되면 +1점을 부여합니다.
- 결과: 제목에 ‘밤요리’가 들어간 문서는 의미 검색 점수가 낮더라도 검색 순위 최상단으로 치고 올라옵니다.
핵심 2: 결과 병합의 우선순위 (Rank Fusion)
검색 결과를 합칠 때 순서가 중요합니다. 블로그 RAG에서는 키워드 매칭 결과를 우선적으로 배치해야 합니다. 사용자가 특정 단어를 언급했다면, 그것이 가장 강력한 검색 의도이기 때문입니다.
핵심 3: AI 프롬프트의 ‘부정 방어’
AI는 기본적으로 확신이 없을 때 “모른다”고 답하는 보수적인 성향이 있습니다. 이를 방지하기 위해 시스템 프롬프트에 강력한 지침을 내립니다.
“자료가 조금이라도 연관되어 있다면 절대 없다고 하지 마세요. 제공된 자료 내에서 최대한 정보를 추출하세요.”
4. 실제 체감 변화
하이브리드 구조 도입 후, 블로그 AI의 성능은 드라마틱하게 변했습니다.
| 항목 | 기존 (Vector 전용) | 개선 후 (Hybrid) |
| 고유 명사 검색 성공률 | 낮음 (오작동 빈번) | 매우 높음 (즉시 탐지) |
| 짧은 키워드 대응 | 거의 불가능 | 완벽 대응 |
| 사용자 만족도 | “왜 못 찾아?”라는 불만 | “정확하네!”라는 반응 |
| “자료 없음” 응답 빈도 | 수시로 발생 | 사실상 사라짐 |
블로그 RAG의 정답은 ‘현실’에 있습니다
우리가 구축하는 것은 거대한 논문 데이터베이스가 아니라, 누군가의 소중한 기록이 담긴 블로그입니다. 블로그 검색의 본질은 결국 “내가 쓴 단어를 AI가 얼마나 잘 찾아내는가”에 달려 있습니다.
의미 검색(AI의 뇌)만 사용하면 똑똑해 보이지만 융통성이 없고, 키워드 검색(전통적 방식)만 사용하면 맥락을 모릅니다. 이 둘을 합친 하이브리드 구조야말로 티스토리, 워드프레스 등 개인 미디어를 위한 RAG 시스템의 진정한 정답입니다.
다음 단계로 나아가기
지금의 하이브리드 구조만으로도 실사용에는 충분합니다. 하지만 더 정교한 시스템을 원하신다면 다음을 고려해 보세요.
- Chunking 최적화: 문서를 문단 단위로 더 잘게 나누기.
- Namespace 분리: 카테고리별로 검색 영역을 나누어 속도 향상.
- 이미지 RAG: 본문 속 이미지 설명(Alt)까지 검색 범위에 포함하기.
AI는 멍청하지 않습니다. 우리가 길을 잘못 알려주었을 뿐입니다.