내 컴퓨터에 직접 AI 검색 시스템을 구축하다 보면 데이터는 분명히 존재하는데 AI가 답변을 못 하거나, 엉뚱한 문서를 가져오는 상황을 마주하게 됩니다. 특히 한국어 RAG(검색형 AI) 시스템에서 고유명사나 전문 용어가 많은 문서를 다룰 때 이러한 문제가 두드러집니다. AI 검색 엔진의 원리부터 실전 구축 방법까지 정리했습니다.
한국어 RAG 검색 성능이 떨어지는 3가지 핵심 원인
파일을 정상적으로 업로드하고 벡터 DB가 작동하더라도 검색 품질이 낮은 이유는 다음과 같습니다.
- 리랭커(Reranker)의 한계: 텍스트 덩어리가 너무 크면 리랭커가 문맥 속의 핵심 단어를 놓치기 쉽습니다.
- 고유명사 매칭 실패: 고유명사나 전문 용어는 벡터 검색(의미 기반)만으로는 정확한 매칭이 어렵습니다.
- 청킹(Chunking) 경계 문제: 정답 데이터가 문장 중간에서 잘려 나가면 검색 유사도가 급격히 하락합니다.
AI 검색의 5가지 주요 방식 이해하기
효과적인 검색 시스템을 만들려면 각 방식의 특징을 이해하고 적재적소에 활용합니다.
1. 키워드 검색 (Lexical Search)
사용자가 입력한 단어와 완벽히 일치하는 단어를 문서에서 찾습니다. 주로 BM25 알고리즘을 사용합니다.
- 장점: 고유명사, 제품 번호, 인물 이름 검색에 매우 강력합니다.
- 단점: 유의어나 문맥을 이해하지 못해 표현이 조금만 달라져도 검색되지 않습니다.
2. 의미 기반 벡터 검색 (Semantic Vector Search)
단어의 철자가 아닌 의미를 다차원 공간의 좌표(벡터)로 변환하여 검색합니다.
- 장점: “괴로움”을 검색했을 때 “고통의 해탈”처럼 의미가 통하는 문서를 찾아냅니다.
- 핵심 도구: 임베딩 모델(BGE-M3 등)과 벡터 DB(Qdrant, ChromaDB 등)가 사용됩니다.
3. RAG (검색 증강 생성) 표준 프로세스
AI 가 정답을 도출하는 3단계 과정입니다.
- 검색(Retrieve): 신뢰할 수 있는 외부 지식 DB에서 관련 문서를 찾아옵니다.
- 재순위화(Rerank): 가져온 문서들 중 질문과 가장 관련 있는 문서를 정밀하게 재정렬합니다.
- 생성(Generate): 선별된 문서를 AI에게 제공하여 답변을 생성합니다.
4. 하이브리드 검색 (Hybrid Search)
키워드 검색의 ‘정확성’과 벡터 검색의 ‘문맥 이해’를 동시에 실행하여 결과를 합치는 방식입니다. 한국어 환경에서는 필수적인 방법입니다.
5. BM25 + 벡터 하이브리드 구축
BM25는 형태소 분석기(Kiwi)가 나눈 토큰(단어 단위)을 기준으로, 질문과 문서 조각(chunk) 사이에서 겹치는 단어의 중요도를 계산해 관련 높은 문서를 상위에 올리는 알고리즘입니다. BM25 알고리즘과 벡터 검색을 병행하는 것이 핵심입니다. 이때 한국어는 형태소 분석기를 통해 단어를 적절히 분리해주어야 검색 정확도가 높아집니다.
데이터 인덱싱과 형태소 분석기 선택
데이터를 DB에 저장하는 인덱싱(Indexing) 과정에서 어떤 도구를 쓰느냐가 승패를 가릅니다.
문서 수집 → 전처리 → 청킹 → 임베딩 → DB 저장
1. 벡터 데이터베이스(Vector DB) 비교
벡터 데이터베이스(Vector DB)는 문장·이미지·문서를 숫자 벡터로 저장하고, 의미가 비슷한 데이터를 빠르게 찾는 데이터베이스입니다. AI 검색, RAG, 추천 시스템에 많이 사용됩니다.
| 구분 | 추천 DB | 특징 |
| 입문 / 개인 프로젝트 | ChromaDB | 파이썬 연동이 매우 쉽고 간편한 설정 |
| 대규모 / 기업용 | Milvus, Pinecone | 수십억 개의 데이터 처리가 가능한 확장성 |
| 속도 중심 | Redis, Qdrant | 빠른 응답 속도와 정밀한 필터링 기능 |
| SQL 활용 | pgvector | 기존 PostgreSQL 지식을 그대로 활용 가능 |
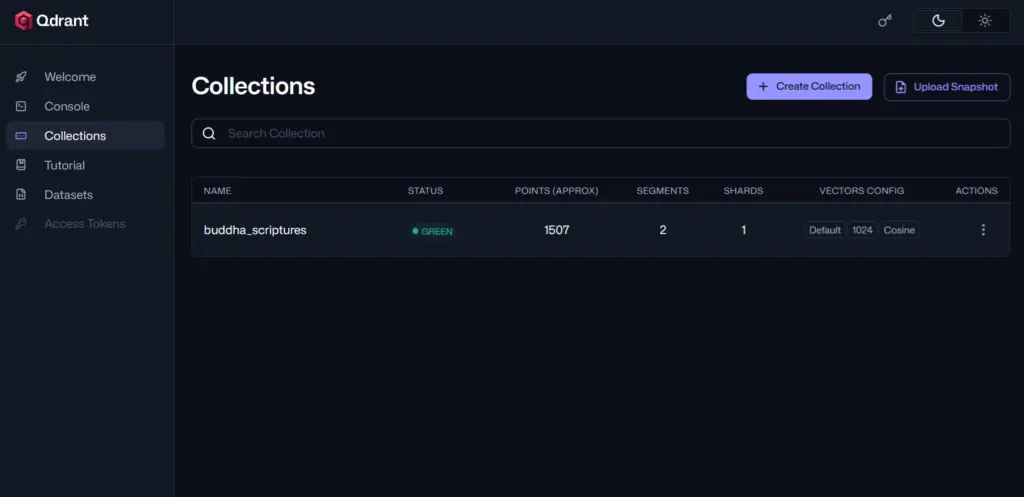
- ChromaDB: 현재 사용 중인 라이브러리입니다. 파이썬 환경에서 설정이 매우 간편하여 프로토타이핑과 소규모 프로젝트에 최강자입니다.
- Milvus: 대규모 데이터를 처리하기 위해 설계된 엔터프라이즈급 DB입니다. 클러스터 구성이 가능해 수십억 개의 벡터를 다룰 때 유리합니다.
- Weaviate: 키워드 검색(BM25)과 벡터 검색을 동시에 수행하는 ‘하이브리드 검색’에 강점이 있으며, GraphQL을 지원합니다.
- Qdrant: Rust 언어로 작성되어 성능과 안정성이 뛰어나며, 필터링 기능이 매우 정밀합니다.
2.형태소 분석기 상세 비교
형태소 분석기는 문장을 의미 단위로 쪼개는 도구입니다. KoNLPy 라이브러리를 통해 다양한 엔진을 사용할 수 있습니다.KoNLPy는 형태소 분석기를 Python 코드에서 쉽게 호출하게 해주는 인터페이스(랩퍼 라이브러리) 입니다.
from konlpy.tag import Okt
from konlpy.tag import Kkma
from konlpy.tag import Komoran
from konlpy.tag import Hannanum
from konlpy.tag import Mecab - Kiwi (추천): 현대 한국어 처리와 복합 명사 분리 능력이 탁월합니다. 설치가 매우 쉽고 윈도우 환경에서 최적의 성능을 보여줍니다.
- MeCab: 처리 속도가 압도적으로 빠릅니다. 대용량 데이터 전처리에 유리하지만 윈도우 설치가 까다로워 리눅스/Docker 환경을 권장합니다.
- Okt: SNS나 리뷰 같은 비정형 텍스트, 짧은 문장 처리에 강점이 있습니다.
- Komoran: 무난한 성능을 보여주며 안정적인 선택지입니다.
- Kkma / Hannanum: 속도가 너무 느리거나 분석 정밀도가 낮아 신규 프로젝트에서는 우선순위가 밀립니다.
실무 기준으로 가장 많이 사용되는 AI 형태소 분석기 6종
| 분석기 | 정밀도 | 신조어 대응 | 처리 속도 | 설치 난이도 | 추천 용도 |
|---|---|---|---|---|---|
| MeCab | 매우 높음 | 보통 (사전 의존) | 압도적 빠름 | 복잡 (C++ 빌드 필요) | 대용량 전처리, 리눅스 서버 |
| Kiwi | 최상 (문맥 기반) | 매우 뛰어남 | 매우 빠름 | 매우 쉬움 (pip) | 범용 NLP, 최신 한국어, 복합명사 |
| Komoran | 높음 | 보통 | 빠름 | 비교적 무난 | 품사 태깅, 일반 전처리 |
| Okt | 중간 | 좋음 (SNS 강점) | 보통 | Java 환경 의존 | SNS, 짧은 문장, 비정형 |
| Kkma | 정교함 | 약함 | 매우 느림 | Java/JPype 이슈 잦음 | 학술적 분석, 기존 코드 유지 |
| Hannanum | 중간 이하 | 약함 | 보통 이하 | KoNLPy 기반 | 가벼운 실험 |
Qdrant 설치 및 운영 방법 (Windows)
가장 안정적이고 빠른 Qdrant를 Docker를 이용해 설치하는 방법입니다.
1단계: Docker Desktop 설치
- Docker 공식 사이트에서 윈도우용 버전을 설치합니다.
- 설치 시 “Use WSL 2 instead of Hyper-V” 옵션을 반드시 체크합니다.
2단계: 서버 실행
터미널(CMD 또는 PowerShell)을 열고 아래 명령어를 실행합니다.
docker run -p 6333:6333 -p 6334:6334 -v qdrant_storage:/qdrant/storage qdrant/qdrant
6333: 대시보드 및 웹 API 포트입니다.-v: 데이터를 로컬 하드에 보존하여 서버를 꺼도 데이터가 유지됩니다.
3단계: 웹 대시보드 활용
브라우저에서 http://localhost:6333/dashboard에 접속하면 생성된 DB 목록(Collections)을 확인하고 벡터 데이터의 분포를 시각적으로 볼 수 있습니다.
Qdrant 설치 및 운영 방법 (Linux)
1. Docker를 이용한 설치 (가장 권장됨)
리눅스 환경에서 의존성 문제 없이 가장 깔끔하게 운영할 수 있는 방법입니다.
Step 1: Qdrant 이미지 다운로드 및 컨테이너 실행
# 최신 이미지를 내려받고 실행합니다.
# 6333: API 포트 / 6334: gRPC 포트
docker run -d -p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage:z \
qdrant/qdrant-v: 호스트의qdrant_storage디렉토리에 데이터를 저장하여 컨테이너 재시작 시에도 데이터가 유지되도록 합니다.6333: Python 클라이언트나 대시보드 접속에 사용됩니다.
2. 바이너리 파일을 직접 설치하는 방법
Docker를 쓸 수 없는 환경일 경우 사용합니다.
# 1. 바이너리 다운로드 (버전은 최신으로 확인 필요)
wget https://github.com/qdrant/qdrant/releases/latest/download/qdrant-x86_64-unknown-linux-gnu.tar.gz
# 2. 압축 해제
tar -xvf qdrant-x86_64-unknown-linux-gnu.tar.gz
# 3. 실행 권한 부여 및 실행
chmod +x qdrant
./qdrant3. 주요 운영 및 관리 방법
① 웹 대시보드 접속
Qdrant는 기본적으로 강력한 Web UI를 제공합니다. 설치 후 브라우저에서 다음 주소로 접속하면 DB 상태와 컬렉션을 시각적으로 관리할 수 있습니다.
- 주소:
http://서버IP:6333/dashboard
② 서비스 상태 확인 (Health Check)
터미널에서 서버가 정상인지 간단히 확인할 수 있습니다.
curl http://localhost:6333/healthz
③ 컬렉션(Collection) 관리 (핵심 개념)
벡터 검색을 위해서는 데이터를 담을 ‘방’인 컬렉션이 필요합니다.
컬렉션 생성 예시 (Python 사용)
from qdrant_client import QdrantClient
from qdrant_client.http import models
client = QdrantClient("localhost", port=6333)
client.create_collection(
collection_name="my_collection",
vectors_config=models.VectorParams(size=1536, distance=models.Distance.COSINE),
)size: 사용 중인 임베딩 모델의 차원 수 (예: BGE-M3는 1024, OpenAI는 1536). distance: 유사도 측정 방식 (Cosines이 가장 보편적).
4. 운영 팁 (Performance & Security)
- 메모리 관리: Qdrant는 인덱스를 메모리에 올려 검색 속도를 높입니다. 데이터가 많아지면 RAM 사용량을 모니터링해야 합니다.
- 보안 설정: 외부망에 노출할 경우 반드시
API_KEY를 설정해야 합니다. Docker 실행 시 환경 변수로 지정 가능합니다. - 백업:
storage디렉토리 전체를 압축해서 백업하거나, Qdrant에서 제공하는SnapshotAPI를 활용하여 운영 중에도 백업을 생성할 수 있습니다.
-e QDRANT__SERVICE__API_KEY=your_secret_key실전 Python 코드 구현
① Kiwi를 활용한 키워드 메타데이터 추출
단순 텍스트뿐만 아니라 핵심 키워드를 따로 추출하여 DB에 함께 저장하면 검색 효율이 올라갑니다.
from kiwipiepy import Kiwi
kiwi = Kiwi()
def extract_keywords(text: str) -> str:
# 명사(NNG, NNP)만 추출
tokens = kiwi.tokenize(text)
nouns = [t.form for t in tokens if t.tag in ('NNG', 'NNP') and len(t.form) > 1]
# 불용어 제거 및 중복 제거 후 상위 15개 반환
stop_words = {'이때', '그때', '모든', '말하였다'}
keywords = [n for n in nouns if n not in stop_words]
return ", ".join(list(dict.fromkeys(keywords))[:15])
② 쿼리 확장(HyDE) 및 메타데이터 활용
사용자의 질문에 핵심 키워드를 덧붙여 검색 성능을 즉시 높이는 방법입니다.
# 1. 쿼리 확장: 질문에 도메인 키워드를 보강
user_text = "선정과 지혜에 관한 가르침"
search_query = f"{user_text} 선정 지혜 결집 게송 천인"
# 2. 메타데이터에 키워드 필드 추가 (인덱싱 시)
payload = {
"link": doc_link,
"title": doc_title,
"documents": chunk_text,
"keywords": extract_keywords(chunk_text),
"summary": chunk_summary
}
한국어 AI 검색 최적화 요약
성공적인 RAG 시스템 구축을 위해 다음 3단계를 기억하세요.
- 환경에 맞는 분석기: 윈도우 개인 PC라면 Kiwi, 리눅스 대용량 서버라면 MeCab을 선택하세요.
- 하이브리드 검색 도입: BM25와 벡터 검색 결과를 RRF(Reciprocal Rank Fusion) 방식으로 병합하고 리랭커로 최종 정렬하세요.
- 데이터 품질 강화: 청킹 시 문장을 겹치게(Overlap) 설정하고, 메타데이터에 키워드 필드를 추가하여 검색 그물망을 촘촘히 만드세요.
이러한 구조만 갖춰도 단순 벡터 검색보다 훨씬 정교하고 똑똑한 한국어 AI 검색 시스템을 완성할 수 있습니다.