음성 AI를 직접 만드는 방법! TTS(Text-to-Speech)를 활용해서 “내 목소리로 말하는 AI”를 직접 구현하는 단계를 알아보고 여러 모델중에서 Bert-VITS2 파인튜닝 사용법을 알아본다.
이 글에서는 한국어 TTS 만들기, 개인 음성 AI 제작, 커스텀 음성 합성 모델을 실제로 바로 따라할 수 있는 Bert-VITS2 파인튜닝 전체 과정을 정리하고, 특히 일반 PC GPU 환경에서도 충분히 실시간에 가까운 음성 생성이 가능한지를 알아보고 가능하다면 개인 개발자나 콘텐츠 제작자들 사이에서 활용도가 높을 것이다.
내가 선택한것은 Bert-VITS2 이다 이 모델을 주목한 이유는 구조 자체가 다르기 때문이다. 단순히 음성을 흉내 내는 방식이 아니라, 먼저 문장의 의미를 BERT가 해석하고 그 결과를 바탕으로 감정과 억양까지 반영해서 음성을 생성한다. 그래서 결과물이 기계음처럼 딱딱하지 않고 실제 사람처럼 자연스럽게 들린다. 그리고 학습이 가능하다는 점이다.
또 하나 중요한 특징은 데이터 요구량이 적다는 점이다.
깨끗한 한국어 음성 기준으로 약 30분에서 1시간 정도만 있어도 충분히 개인 목소리 TTS를 만들 수 있다. 이미 기본 모델이 수만 명의 발음, 억양, 리듬을 학습해 둔 상태이기 때문에, 여기에 개인 음성 특징만 추가로 학습시키는 구조이기 때문이다.
Bert-VITS2가 특별한 이유는 아래와 같다.
- 감정·억양 이해: 단순히 소리를 흉내 내는 게 아니라, 문장의 문맥을 BERT가 먼저 해석해서 감정과 억양이 자연스럽게 반영된다.
- 빠른 추론 속도: GPT-SoVITS처럼 자기회귀(Autoregressive) 방식을 쓰지 않아 중급 GPU에서도 실시간에 가까운 음성 생성이 가능하다.
- 짧은 데이터로 고품질: 깨끗한 한국어 음성 데이터 30분~1시간만 있어도 놀라울 정도로 자연스러운 커스텀 TTS를 만들 수 있다.
Bert‑VITS2는 VITS2 음성 합성 구조와 BERT 기반 텍스트 인코딩을 결합한 오픈소스 TTS(Text‑to‑Speech) 모델로, GitHub 기반 커뮤니티에서 개발·확장된 프로젝트이다. 한국어 적용을 시도한 여러 커뮤니티 포크 프로젝트가 존재하며, 한국어 G2P나 BERT 모델을 활용한 실험적 구현도 진행되고 있다. 다만 이러한 한국어 구현은 대부분 비공식 포크 또는 실험 단계로, 완성된 공식 한국어 모델이 존재하는 것은 아니다. 그러나 아래 방법으로 진행하면 한국어 학습이 가능하다.
목차
1. TTS 파인튜닝이란 무엇인가?
1-1. “파인 튜닝(Fine-tuning)”을 쉽게 이해하기
한국어 음성 AI 파인튜닝이란, 이미 “말하는 법”을 알고 있는 기본 모델(Pre-trained Model)을 특정 목소리 — 즉, 특정 목소리 — 에 맞게 추가 학습시키는 과정이다.
처음부터 AI에게 “말하는 법”을 가르치려면 수만 명의 음성 데이터와 수천 시간의 계산이 필요하다. 하지만 파인튜닝은 다르다.
| 구분 | 내용 |
|---|---|
| 기본 모델 (Pre-trained) | 한국어 발음·억양·문법·기본 소리 내는 법을 이미 학습 완료 |
| 내 데이터 (파인튜닝용) | “그 기본 목소리 말고, 내 목소리 톤으로 바꿔줘”라고 추가 교육 |
그림을 아주 잘 그리는 화가에게 내 얼굴 사진을 몇 장 주고, “내 화풍으로 나를 그려줘” 라고 추가 교육시키는 것과 정확히 같은 원리다.
1-2. 왜 30분 데이터로도 가능한가?
기본 모델은 수만 명의 목소리를 통해 이미 발음·리듬·에너지·주파수 패턴을 폭넓게 학습했다. 파인튜닝은 그 위에 내가 원하는 목소리 특성만 덧씌우는(overlay) 방식이기 때문에, 적은 데이터로도 놀라운 결과를 낼 수 있다.
Pre-trained Model (수만 명 데이터) + 특정 목소리 30분 = 나만의 AI TTS 완성
2. Bert-VITS2 내부 동작 원리
딥러닝 TTS가 실제로 어떻게 돌아가는지 이해하면, 나중에 에러가 났을 때 원인을 훨씬 빠르게 파악할 수 있다. Bert-VITS2의 학습 과정은 크게 세 가지로 나눌 수 있다.
git clone https://github.com/fishaudio/Bert-VITS2.git
cd Bert-VITS22-1. 문장의 의미 파악 — BERT 인코더
텍스트가 입력되면 BERT(Bidirectional Encoder Representations from Transformers) 가 가장 먼저 작동한다. BERT는 문장 전체의 앞뒤 문맥을 동시에 보며 이 문장이 슬픈지·기쁜지·질문인지를 파악하고, 그 결과를 벡터(숫자 배열)로 압축한다. 이 벡터가 이후 음성 생성의 감정·억양 기초 정보로 쓰인다.
파인튜닝 중 화면에 bert loss가 표시된다면, BERT가 내가 요구하는 감정 스타일을 얼마나 잘 해석하는지 학습하는 수치다. 이 값이 낮아질수록 억양이 자연스러워진다.
2-2. 발음과 음성 파형의 매칭 — VITS2 디코더
BERT가 의미를 파악하면, VITS2(Variational Inference Text-to-Speech 2) 가 각 발음 기호를 실제 음성 파형의 해당 구간에 정렬(alignment)한다.
예를 들어 “안”이라는 소리가 특정 목소리에서 어떤 주파수(Hz)와 에너지(dB)를 가지는지, 멜 스펙트로그램(Mel-spectrogram) 단위로 학습하는 단계다. 멜 스펙트로그램은 인간의 청각 특성에 맞게 변환된 주파수 지도로, 이 지도가 정교해질수록 출력 음성이 “기계 티 없이” 들리게 된다.
3-3. 무한 반복 연습 — GAN 기반 학습 루프
Bert-VITS2는 GAN(Generative Adversarial Network) 구조를 차용해 품질을 높인다.
생성기(Generator) ──────→ "이 소리가 설정 목소리랑 비슷해?"
↑ ↓
판별기(Discriminator) ←──── "아직 기계 티가 나. 더 자연스럽게!"- 생성기: 입력 텍스트로부터 가짜 목소리를 만든다.
- 판별기: 진짜 목소리와 가짜 목소리를 구별하려 한다.
- 학습: 생성기는 판별기를 속이도록, 판별기는 더 날카롭게 구별하도록 서로 경쟁하며 수만 번 반복한다.
이 과정에서 화면에 출력되는 Loss(손실) 숫자들은 실제 목소리와 AI가 만든 소리의 차이를 나타낸다. Loss가 0에 가까워질수록 원하는 목소리와 구분이 안 갈 정도로 정교해진다.
| 학습 중 표시 항목 | 의미 |
|---|---|
loss/g/total | 생성기 전체 손실 (낮을수록 좋음) |
loss/d/total | 판별기 전체 손실 (균형 유지가 중요) |
loss/g/mel | 멜 스펙트로그램 유사도 (핵심 품질 지표) |
loss/g/kl | KL 다이버전스 — 잠재 공간의 분포 정렬 |
loss/g/fm | Feature Matching — 세부 음색 유사도 |
3. 모델 선택 방법 — Bert-VITS2와 경쟁 모델 비교
한국어 커스텀 TTS를 만들 때 자주 비교되는 모델들을 정리했다. 실제로 선택하기 전에 이 표를 꼭 참고하자.
3-1. 주요 모델 비교표
| 모델명 | 실사 품질 | 추론 속도 | 학습 난이도 | 데이터 요구량 | 특이사항 |
|---|---|---|---|---|---|
| Bert-VITS2 | ⭐⭐⭐⭐⭐ | ⚡⚡⚡⚡ | 보통 | 30분~1시간 | 감정·억양 자연스러움 최상 |
| GPT-SoVITS | ⭐⭐⭐⭐⭐ | ⚡⚡ | 보통 | 1~3분 (제로샷) | 제로샷 복제 강점, 속도 느림 |
| Original VITS | ⭐⭐⭐⭐ | ⚡⚡⚡⚡⚡ | 쉬움 | 1시간 이상 | 가장 가볍고 빠름 |
| VITS-fast-fine-tuning | ⭐⭐⭐⭐ | ⚡⚡⚡⚡ | 매우 쉬움 | 30분 | 튜토리얼 풍부, 입문용 |
| XTTS v2 | ⭐⭐⭐⭐ | ⚡⚡⚡ | 쉬움 | 6초 (제로샷) | 다국어 지원 강점 |
| StyleTTS2 | ⭐⭐⭐⭐ | ⚡⚡⚡ | 어려움 | 1시간 이상 | 스타일 전이 특화 |
| CosyVoice2 | ⭐⭐⭐⭐ | ⚡⚡⚡ | 보통 | 제로샷 가능 | Alibaba 개발, 최신 모델 |
| Piper ONNX KSS Korean | ⭐⭐⭐ | ⚡⚡⚡⚡⚡ | 쉬움 | 불필요 | 경량 로컬 실행 특화 |
3-2. 어떤 상황에서 무엇을 선택할까?
- 사람 같은 목소리 + 로컬 실행 +저사양 RTX 2060 → Bert-VITS2 (이 글의 주제)
- 최대한 빠른 제작 + 입문 → VITS-fast-fine-tuning
- 극소량 데이터로 제로샷 복제 → GPT-SoVITS 또는 XTTS v2
- 다국어 서비스 → XTTS v2 또는 CosyVoice2
- 초경량 임베디드 배포 → Piper ONNX KSS Korean
결론: 뉴스 브리핑, 팟캐스트, 유튜브 AI 내레이터처럼 “내 목소리로, 실시간에 가깝게, 저사양 로컬에서” 쓰고 싶다면 현재 시점에서 Bert-VITS2가 가장 균형 잡힌 선택이다.
4. 전체 제작 로드맵 (3단계)
내 목소리 AI TTS 만들기의 전체 흐름을 한눈에 보자.
┌─────────────────────────────────────────────────────────────────┐
│ STEP 1: 환경 구축 │
│ Python 가상환경 → 라이브러리 설치 → GitHub 소스 내려받기 │
│ 예상 소요 시간: 1~2시간 │
├─────────────────────────────────────────────────────────────────┤
│ STEP 2: 데이터 준비 (가장 중요) │
│ 녹음 원본 → 슬라이싱(5~10초) → 전사(Whisper) → 노이즈 제거 │
│ 예상 소요 시간: 녹음 길이에 따라 30분~2시간 │
├─────────────────────────────────────────────────────────────────┤
│ STEP 3: 파인튜닝 실행 │
│ BERT 특징 추출 → 학습 시작(train_ms.py) → 모델 파일 추출 │
│ 예상 소요 시간: RTX 2060 기준 1~8시간 │
└─────────────────────────────────────────────────────────────────┘⚠ 핵심 원칙: 모델보다 데이터의 질이 우선이다. 아무리 좋은 모델도 잡음 섞인 데이터로는 실사 품질이 나오지 않는다.
1. 학습 단계별 비교 및 상세 분석
학습의 목적과 데이터 규모에 따라 세 가지 단계로 구분한다. 각 단계는 모델의 초기화 상태와 연산 자원의 효율성에 직접적인 영향을 미친다.
| 구분 | 사전 학습 (Pre-training) | 미세 조정 (Fine-tuning) | 추가 학습 (Incremental Learning) |
| 개념 | 아무것도 모르는 상태에서 언어의 기초를 학습한다. | 특정 목소리의 고유한 특징을 집중적으로 학습한다. | 기존 모델에 새로운 데이터를 추가하여 성능을 개선한다. |
| 데이터량 | 수천 시간 이상의 방대한 음성을 사용한다. | 수십 분에서 수 시간의 특정 음성을 사용한다. | 기존 데이터에 새로 추가된 데이터를 병합하여 사용한다. |
| 소요 시간 | 수주에서 수개월이 소요되며 대규모 GPU 자원이 필요하다. | 수 시간에서 수일 내에 완료되며 개인 GPU로 가능하다. | 수 시간 내외로 빠르게 완료된다. |
| 가중치 | 가중치를 처음부터 생성한다. | 사전 학습된 가중치에서 시작한다. | 이전에 학습 완료된 .pth 파일에서 시작한다. |
[보충 설명]
사전 학습은 모델의 뼈대를 만드는 작업이므로 개인 환경에서는 불가능에 가깝다. 따라서 개인 사용자는 이미 완성된 베이스 모델을 가져와 미세 조정하거나, 특정 단어의 발음 등을 교정하기 위해 추가 학습을 진행하는 방식이 가장 효율적이다. 특히 VITS2는 기존 VITS보다 효율적인 아키텍처를 가지므로 적은 데이터로도 높은 품질을 기대할 수 있다.
2. 주요 설정 값 (Config) 및 최적화 전략
사용 중인 비디오카드 환경은 VRAM 용량이 제한적이므로, 메모리 효율을 높이면서 학습 안정성을 확보하는 설정이 필수적이다.
학습 단계별 주요 설정값 비교
| 설정 항목 (Key) | 사전 학습 (Pre-training) | 미세 조정 (Fine-tuning) | 추가 학습 (Incremental) | 설정 사유 및 주의사항 |
| batch_size | 8 ~ 16+ (다중 GPU) | 2 ~ 4 | 1 ~ 2 | 데이터가 적은 추가 학습일수록 배치를 작게 가져가며 정교하게 학습한다. |
| learning_rate | 2e-4 (0.0002) | 1e-4 (0.0001) | 5e-5 ~ 1e-5 | 이미 완성된 가중치를 보존하기 위해 단계가 뒤로 갈수록 학습률을 낮춘다. |
| betas | [0.8, 0.99] | [0.8, 0.99] | [0.9, 0.999] | 추가 학습 시에는 모멘텀 값을 높여 급격한 변화를 방지하기도 한다. |
| eps | 1e-9 | 1e-9 | 1e-9 | 수치적 안정성을 위한 값으로 일반적으로 유지한다. |
| epochs | 1000+ | 100 ~ 500 | 50 ~ 100 | 단계별로 필요한 반복 횟수가 급격히 줄어든다. |
| test_duration | 길게 (수백 개) | 짧게 (10~20개) | 매우 짧게 (5개 미만) |
[보충 설명]
학습 속도를 높이려면 fp16(Half Precision) 학습 설정을 활성화하는 것이 유리하다. 또한, 백그라운드에서 VRAM을 점유하는 다른 프로세스를 종료하여 학습 가용 공간을 최대한 확보해야 한다. 만약 학습 중 에러가 발생한다면 가장 먼저 batch_size를 1로 줄이거나 음성 데이터의 최대 길이를 제한하는 설정을 검토해야 한다.
5. 1단계 — 환경 구축 및 라이브러리 설치
이 섹션은 RTX 2060(6GB~12GB) 환경에 최적화된 설치 방법이며, 가장 관리가 편한 Bert-VITS2 v2.3 버전을 기준으로 한다.
5-1. 작업 폴더 생성 및 Python 가상환경 설정
가상환경을 쓰는 이유는 간단하다. 프로젝트마다 다른 라이브러리 버전이 충돌하지 않도록 격리된 Python 공간을 만들기 위해서다. 특히 TTS 딥러닝 환경은 PyTorch 버전에 민감하기 때문에 반드시 가상환경을 사용해야 한다.
# 폴더 생성 및 이동 (드라이브와 경로는 본인 환경에 맞게 수정)
mkdir G:\naver_ai\Bert-VITS2
cd G:\naver_ai\Bert-VITS2
# 가상환경 생성 (Python 3.10 권장 — 3.11 이상은 일부 패키지 호환 문제 발생 가능)
python -m venv venv
# 가상환경 활성화 (이후 모든 pip 명령은 이 상태에서 실행)
.\venv\Scripts\activatePython 버전 주의: Bert-VITS2는 Python 3.10이 가장 안정적이다.
python --version으로 먼저 확인하자.
5-2. PyTorch 및 CUDA 설치 (GPU 가속 핵심)
RTX 2060의 GPU 가속(CUDA)을 활용하려면 CUDA 버전에 맞는 PyTorch를 설치해야 한다. RTX 2060은 CUDA 11.8을 완벽하게 지원한다.
# GPU 가속 PyTorch 설치 (CUDA 11.8 기반)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118설치 후 확인: Python 인터프리터에서
import torch; print(torch.cuda.is_available())를 실행해True가 나오면 GPU 가속이 정상 작동한다.
5-3. 필수 라이브러리 전체 설치
Bert-VITS2 파인튜닝에 필요한 모든 라이브러리를 설치한다. 각 패키지가 어떤 역할을 하는지 주석으로 함께 정리했다.
# 기본 의존성 패키지
pip install ffio pyopenjtalk six
pip install tensorboard # 학습 과정 시각화 도구
pip install PyYAML tqdm numpy requests pandas flask setuptools
pip install huggingface_hub # HuggingFace에서 사전 학습 모델 자동 다운로드
# 언어 모델 및 텍스트 처리
pip install loguru einops local-attention transformers
pip install sentencepiece # 서브워드 토크나이저
# 한국어·중국어·일본어 텍스트 정규화
pip install pypinyin jieba cnert g2pk2
pip install cn2an # 중국어 숫자 정규화
pip install num2words # 숫자→문자 변환
pip install g2pK jamo # 한국어 자모 처리
pip install g2p_en inflect # 영어 발음 기호 변환
pip install python-mecab-ko # 한국어 형태소 분석
pip install mecab-python3 unidic-lite # 일본어 형태소 분석
# 오디오 처리
pip install pydantic pyyaml scipy soundfile
pip install vector-quantize-pytorch
# 나머지 의존성
pip install mace g2pk이후 requirements.txt가 있다면 한 번에 설치도 가능하다:
pip install -r requirements.txt5-4. GitHub에서 Bert-VITS2 소스 코드 내려받기
# 1. 현재 폴더를 Git 저장소로 초기화
git init
# 2. GitHub 원격 저장소 주소 등록
git remote add origin https://github.com/fishaudio/Bert-VITS2.git
# 3. 파일 목록 가져오기
git fetch
# 4. 소스 코드 강제 덮어쓰기 (기존 venv 폴더는 유지됨)
git checkout -t origin/master -f5-5. 필수 사전 학습 모델(Pre-trained Model) 다운로드
Bert-VITS2는 ‘생목소리’를 만드는 게 아니라 이미 학습된 기본 모델 위에 내 목소리를 입히는 방식이다. 따라서 아래 두 가지 파일을 반드시 먼저 준비해야 한다.
| 파일 | 역할 | 다운로드 위치 |
|---|---|---|
BERT 모델 (bert-base-multilingual-cased 등) | 한국어 문맥 이해 | HuggingFace Hub (자동 다운로드 가능) |
Base 음성 모델 (D_0.pth, G_0.pth) | 기본 목소리 골격 | Bert-VITS2 공식 배포처 |
자동 다운로드:
bert_gen.py실행 시 BERT 모델이 없으면 자동으로 HuggingFace에서 내려받는다. 단, 네트워크 속도에 따라 상당한 시간이 걸릴 수 있다.
6. 2단계 — 학습 데이터 준비 및 자동 전처리
내 목소리 AI TTS 품질의 80%는 이 단계에서 결정된다. 데이터 준비를 소홀히 하면 아무리 좋은 모델을 써도 기계음이 섞이거나 발음이 뭉개진다.
6-1. 데이터셋 폴더 구조 만들기
G:\naver_ai\Bert-VITS2\
└── Data\
└── my_voice\
├── raw\ ← 원본 긴 음성 파일 (.wav, .mp3)을 여기에
├── wavs\ ← 자동 슬라이싱된 5~10초 파일들이 저장됨
└── short_character_anno.list ← 전사 대본 목록 파일mkdir Data
mkdir Data\my_voice
mkdir Data\my_voice\raw
mkdir Data\my_voice\wavs프로젝트 루트/
│
├── 핵심 실행/모델 관련
│ ├── configs/ # 설정 파일 디렉토리
│ ├── Data/ # 학습 데이터 및 모델 저장소
│ │ ├── models/ # 학습된 모델 가중치 (.pth 파일)
│ │ ├── filelists/ # 데이터 파일 목록
│ │ └── my_voice/ # 사용자 음성 데이터 (raw/wavs)
│ ├── models/ # 모델 관련 파일
│ └── pretrained_models/ # 사전 학습된 모델
│
├── 언어/텍스트 처리
│ ├── bert/ # BERT 관련 모델 (중국어/일본어)
│ ├── text/ # 텍스트 처리 모듈
│ ├── tools/ # 도구 모음 (번역, 문장 분할 등)
│ ├── emotional/ # 감정 인식 모델 (CLAP, wav2vec2)
│ └── slm/ # SLM 모델 (wavlm-base-plus)
│
├── 버전 호환성
│ ├── oldVersion/ # 이전 버전 코드 (V1.0 ~ V2.2)
│ │ ├── V101, V110, V111, V200, V210, V220
│ ├── onnx_modules/ # ONNX 추론 모듈 (V2.0 ~ V2.4)
│ │ ├── V200_OnnxInference, V210_OnnxInference, V220_OnnxInference
│ │ └── V240_OnnxInference (JP/ZH 버전)
│ └── monotonic_align/ # Monotonic Alignment 알고리즘
│
├── UI/웹 관련
│ ├── css/ # 스타일 시트
│ ├── img/ # 이미지 리소스
│ └── for_deploy/ # 배포 관련 파일
│
├── 가상환경 (venv)
│ ├── Lib/site-packages/ # 설치된 패키지들
│ │ ├── torch, torchaudio, torchvision # PyTorch 생태계
│ │ ├── gradio, fastapi, uvicorn # 웹 프레임워크
│ │ ├── transformers, tokenizers, bert # NLP/Hugging Face
│ │ ├── librosa, soundfile, soxr # 오디오 처리
│ │ ├── numpy, scipy, pandas # 수치 연산
│ │ ├── nltk, konlpy, jieba, mecab # 형태소 분석
│ │ ├── g2p, g2pk, g2p_en # 그래핀-음소 변환
│ │ └── ... (200+ 패키지)
│ ├── Scripts/ # 실행 스크립트
│ └── share/ # 공유 리소스
│
└── __pycache__/ # 컴파일된 파이썬 바이트코드6-2. 데이터 품질 기준 — 실사 목소리의 전제 조건
| 항목 | 요구사항 | 중요도 |
|---|---|---|
| 배경음 | 배경음악, 에코, 잔향 절대 금지 | ⭐⭐⭐⭐⭐ |
| 마이크 품질 | 다이나믹 또는 콘덴서 마이크 권장 | ⭐⭐⭐⭐ |
| 파일 형식 | 44.1kHz vs 16/22.05kHz 모노(Mono) 설정 | ⭐⭐⭐⭐ |
| 발화 속도 | 너무 빠르거나 느리지 않은 자연스러운 속도 | ⭐⭐⭐ |
| 문장 다양성 | 단조로운 문장보다 다양한 억양·감정 포함 | ⭐⭐⭐ |
| 분량 | 최소 30분, 권장 1~2시간 | ⭐⭐⭐⭐ |
배경음악이 있으면 왜 안 되나? AI가 배경음악의 주파수 패턴까지 “내 목소리”로 학습해버린다. 결과물에 이상한 하울링이나 음악 느낌이 섞이는 원인이다. 이제 실제 작업을 진행 한다
6-3. 자동 슬라이싱 + Whisper 전사 스크립트
학습 명령어 요약
1. python preprocess.py ---short_character_anno.list 생성
2. python preprocess_text.py --transcription-path Data/my_voice/short_character_anno.list --config-path configs/config.json
---short_character_anno.list.cleaned,train.list,val.list , 생성
3. python bert_gen.py --config-path configs/config.json
-- sample.bert.pt 생성
이작업은 긴 음성 파일을 5~10초 단위로 자르고, 각 조각의 내용을 자동으로 텍스트로 변환하는 작업이고 아래 코드는 AI(OpenAI Whisper)로 완전 자동화하는 스크립트다.
이 코드는 흩어져 있는 원본 음성 파일을 그대로 쓰는 게 아니라, 학습에 맞게 잘게 나누고 자동으로 자막까지 붙여주는 전처리 과정을 한 번에 처리한다.
먼저 Data/my_voice/raw 폴더 안에 있는 음성 파일들을 하나씩 읽어온다. 이때 wav나 mp3만 대상으로 삼고, 나머지는 건너뛴다. 불러온 음성은 바로 쓰지 않고, 사람이 말하지 않는 구간(무음)을 기준으로 자연스럽게 여러 조각으로 나눈다. 긴 녹음을 그대로 학습시키면 모델이 제대로 패턴을 못 잡기 때문에, 이런 식으로 문장 단위에 가깝게 쪼개는 게 핵심이다.
잘린 조각들 중에서도 너무 짧은 것들은 버린다. 짧은 발화는 학습에 오히려 노이즈가 되기 때문이다. 남은 조각들은 모두 44.1kHz vs 16/22.05kHz 모노(Mono) 형태로 다시 저장되는데, 이건 Bert-VITS2가 가장 안정적으로 학습하는 형식에 맞추기 위한 처리다.
Whisper 모델 체급별 비교
Whisper는 모델 크기가 커질수록 매개변수(Parameter)가 많아져 인식률이 정교해지지만, 더 많은 VRAM과 연산 시간을 요구한다.
| 모델명 | 매개변수 | 요구 VRAM | 속도 | 한국어 정확도 | 추천 용도 |
| tiny | 39 M | 약 1 GB | 매우 빠름 | 낮음 | 단순 테스트용 |
| base | 74 M | 약 1 GB | 빠름 | 보통 | 빠른 초안 작업 |
| small | 244 M | 약 2 GB | 보통 | 좋음 | 가성비 및 균형 (추천) |
| medium | 769 M | 약 5 GB | 느림 | 매우 좋음 | 고품질 데이터셋 구축 |
| large-v3 | 1.55 B | 약 10 GB | 매우 느림 |
그 다음 단계가 이 코드의 핵심인데, 잘린 각 음성 파일을 Whisper 모델에 넣어서 자동으로 텍스트를 뽑아낸다. 즉, 사람이 직접 스크립트를 쓰지 않아도 음성 → 텍스트 변환이 자동으로 이루어진다. 여기서 언어를 한국어로 고정해서 인식 정확도를 높인다.
이렇게 얻은 텍스트와 음성 파일 경로를 묶어서 한 줄씩 기록하는데, 형식은음성경로 | 화자이름 | 언어코드 | 텍스트
이 구조로 저장된다. 이 파일이 바로 Bert-VITS2 학습에서 사용하는 핵심 입력 데이터다.
먼저 필요한 도구를 설치한다:
# 오디오 처리 도구
pip install pydub librosa auditok
# 음성 → 텍스트 자동 전사 (OpenAI Whisper)
pip install openai-whisper이 코드를 실행하면 데이터는 자동으로 만들어지지만, 그 상태가 바로 “완성 데이터”는 아니다. Whisper가 만든 텍스트는 편하긴 한데, 발음이 빠르거나 잡음이 있으면 틀린 문장이 꽤 섞인다. 모델은 그걸 그대로 “정답”이라고 배우기 때문에, 한 번 틀어지면 발음이 이상해지는 원인이 된다
그래서 전처리 이후에 반드시 해야 하는 작업이 하나 있다.Data/my_voice/short_character_anno.list 파일을 열어서, 각 줄에 있는 텍스트를 사람이 음성을 들으며 눈으로 확인하고 틀린 부분만 고쳐주는 과정이 필요하다.
6-4. 전처리 스크립트 실행 방법 (python preprocess.py)
1. 학습시킬 긴 음성 파일을 Data/my_voice/raw 폴더에 넣는다.
2. 터미널에서: python preprocess.py 를 실행한다.
3. Data/my_voice/wavs 에 잘린 파일들이 생기고
short_character_anno.list 에 대본이 적히면 성공.1. python preprocess.py ---short_character_anno.list 생성6-5. 텍스트 전처리 (preprocess_text.py)
전사 목록 파일이 준비됐으면, 텍스트 전처리를 실행해 학습용 형식으로 변환한다.short_character_anno.list에 들어 있는 음성 파일 경로와 텍스트를 불러와서, 사람이 읽는 문장을 모델이 이해할 수 있는 형태로 바꿔준다.
먼저 텍스트를 그대로 쓰지 않고 한 번 정리한다. 숫자는 발음으로 풀어주고, 불필요한 기호는 정리하고, 실제 사람이 읽는 소리에 가깝게 다듬는다. 그 다음에는 이 문장을 더 잘게 쪼개서 음소 단위로 바꾼다. 즉, “안녕하세요” 같은 문장을 모델이 발음 단위로 이해할 수 있도록 변환하는 과정이다.
이 과정에서 단순히 글자만 바꾸는 게 아니라, 각 음소의 길이나 억양에 맞는 정보도 같이 만들어진다. 이 정보들이 나중에 모델이 자연스럽게 말하도록 만드는 핵심 역할을 한다.
2. python preprocess_text.py --transcription-path Data/my_voice/short_character_anno.list --config-path configs/config.json
---short_character_anno.list.cleaned,train.list,val.list , 생성6-6. BERT 특징 벡터 추출 (bert_gen.py)
텍스트 전처리가 끝나면 각 문장에 대한 BERT 감정·문맥 벡터를 미리 계산해 저장한다. 학습 중 매번 BERT를 돌리는 것보다 미리 뽑아두는 게 훨씬 효율적이다.
주요 언어 모델(BERT) 비교 및 역할
한국어 음성 합성(TTS)의 품질은 텍스트를 분석하는 BERT 모델에 의해 결정된다. BERT는 문맥을 파악하여 적절한 끊어 읽기, 성조(Pitch), 억양을 생성 모델에 전달하는 핵심 역할을 수행한다.
| 모델 구분 | 모델명 (Hugging Face) | 역할 및 특징 | 추천도 및 비고 |
| 한국어 기본 | kykim/bert-kor-base | 한국어 구어체와 문맥 분석에 최적화되어 자연스러운 한국어 발음을 생성한다. | 필수 (High) / 가장 범용적임 |
| 한국어 성능 | skt/kobert-base-v1 | SKT에서 공개한 모델로, 한국어의 특성을 잘 반영하여 문장 구조 파악 능력이 우수하다. | 선택 (Medium) / 발음 정확도 향상 |
| 영어 전용 | microsoft/deberta-v3-large | 영어 문장 및 기술 용어 분석 능력이 탁월하여 다국어 합성 시 정확도를 높여준다. | 필수 (High) / 외래어 처리용 |
| 다국어 통합 | google-bert/bert-base-multilingual-cased | 여러 언어를 동시에 처리할 때 사용하며, 한국어와 영어가 섞인 문장에서 안정적인 성능을 보인다. | 권장 (Medium) / 혼용 문장 최적화 |
| 감정 분석 | monologg/koelectra-base-v3-discriminator | 문장의 감정 상태를 세밀하게 파악하여 감정이 실린 음성을 생성할 때 유리하다. | 선택 (Low) / 감정 특화 모델용 |
이 명령어는 전처리보다 한 단계 더 들어간 작업이다.
앞에서 텍스트를 음소로 쪼개고 학습용 리스트를 만들었다면, 여기서는 그 텍스트에 의미 정보까지 덧붙이는 과정을 한다.
최신 버전 다운로드 명령어
터미널(PowerShell)에서 허깅페이스의 최신 모델 파일들을 폴더 구조에 맞춰 한 번에 다운로드하는 명령어입니다. git-lfs가 설치되어 있어야 대용량 파일(pytorch_model.bin)이 정상적으로 받아집니다.
한국어 전용 모델 다운로드 (추천)
# 작업 드라이브의 작업 폴더 내 bert 폴더로 이동 후 실행
git clone https://huggingface.co/kykim/bert-kor-base
영어/다국어 모델 다운로드
git clone https://huggingface.co/microsoft/deberta-v3-large
bert_gen.py는 말 그대로 BERT 모델을 이용해서 각 문장에 대한 문맥 임베딩(의미 벡터)을 미리 계산해 두는 작업이다. 사람이 같은 단어라도 문장에 따라 다르게 읽는 것처럼, 모델도 단순한 음소 정보만으로는 자연스러운 발음을 만들기 어렵다. 그래서 문장의 흐름, 강조, 어조 같은 걸 반영하기 위해 BERT를 통해 문장을 한 번 더 해석해 주는 것이다.
이 과정에서는 train.list나 val.list에 있는 텍스트를 하나씩 읽어서, 각 문장에 대응되는 BERT 특징을 계산하고 파일로 저장한다. 이렇게 만들어진 데이터는 학습할 때 매번 BERT를 돌리지 않아도 되게 해 주기 때문에 속도도 빨라지고, 무엇보다 학습할 때와 추론할 때의 조건을 맞춰주는 역할을 한다.
3. python bert_gen.py --config-path configs/config.json
-- sample.bert.pt 생성실행하면 각 음성 파일 경로와 동일한 위치에 .bert.pt 파일이 생성된다. 진행 바(Progress Bar)가 올라가면 정상이다.
주의: 이 단계에서 BERT 모델 파일이 없으면 자동 다운로드를 시도한다. 네트워크 속도에 따라 시간이 걸릴 수 있으며, 완료 후에는 오프라인에서도 실행 가능하다.
전체 구조 요약 표
단계 코드 입력 처리 내용 정제/필터 역할 출력 저장 위치 1 preprocess.py raw wav/mp3 음성 분할 + Whisper STT 무음 기준 분할 / 2초 이하 제거 wav chunk + text Data/my_voice/wavs/+short_character_anno.list2 preprocess_text.py short_character_anno.list 데이터 구조화 형식 검사 + wav 존재 확인 + 중복 제거 train/val split + config 수정 Data/filelists/3 cleaner.py text + language 텍스트 → phoneme 변환 ✔ 텍스트 정규화✔ 언어별 g2p 변환✔ 발음 실패 제거 norm_text + phones + tones + word2ph 메모리 (중간 결과) 4 bert_gen.py train/val list BERT embedding 생성 길이 mismatch 제거 / 없는 bert 재생성 .bert.pt wav 옆
| 단계 | 실행 파일 | 생성 파일 | 내용 | 저장 위치 |
|---|---|---|---|---|
| 1 | preprocess.py | wav chunk 파일 | 원본 음성 → 잘린 학습용 음성 | Data/my_voice/wavs/ |
| 1 | preprocess.py | short_character_anno.list | wav + 텍스트 라벨 생성 | Data/my_voice/ |
| 2 | preprocess_text.py | train.list | 학습용 데이터 리스트 | Data/filelists/ |
| 2 | preprocess_text.py | val.list | 검증용 데이터 리스트 | Data/filelists/ |
| 2 | preprocess_text.py | .cleaned (옵션) | 정제된 중간 텍스트 | Data/filelists/ |
| 2 | preprocess_text.py | config.json (수정) | speaker ID + train/val 경로 업데이트 | configs/config.json |
| 3 | bert_gen.py | *.bert.pt | 텍스트 → BERT 임베딩 | Data/my_voice/wavs/ (wav 옆) |
7. 3단계 — 파인튜닝(학습) 실행
데이터 준비가 모두 끝났다. 이제 실제 AI 음성 파인튜닝을 시작할 시간이다.
7-1. 학습 실행 명령어
# 기본 실행
python train_ms.py -c configs/config.json -m Data
# 메모리 에러(오류 코드 1455) 방지용 — RTX 2060 권장 설정
python train_ms.py -c configs/config.json -m Data --num_workers 0
--num_workers 0옵션을 사용하면 멀티프로세싱 과정에서 발생하는 Windows 특유의 메모리 에러를 방지할 수 있다.
7-2. 원클릭 자동 학습 배치 파일
매번 명령어를 치기 번거롭다면, 아래 내용으로 train_auto.bat 파일을 만들어 두자:
@echo off
title Bert-VITS2 Auto Trainer
cd /d G:\naver_ai\Bert-VITS2
echo 1/3] 가상환경 활성화 중...
call .\venv\Scripts\activate
echo 2/3] 불필요한 Python 프로세스 종료 (메모리 확보)...
taskkill /f /im python.exe /t 2>&1
echo 3/3] 학습 시작 (Batch 2, Workers 0)...
:: --num_workers 0 옵션으로 메모리 에러(1455) 방지
python train_ms.py -c configs/config.json -m Data --num_workers 0
pause이 파일을 더블클릭하면 가상환경 활성화부터 학습 시작까지 자동으로 진행된다.
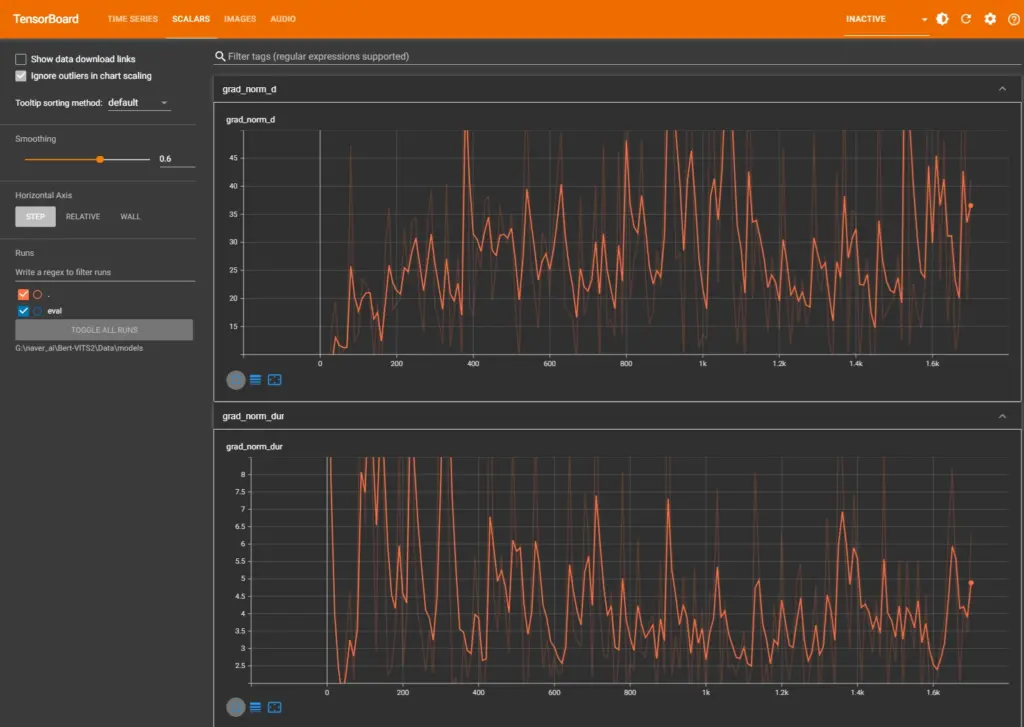
7-3. 학습 진행 중 모니터링 — TensorBoard 활용
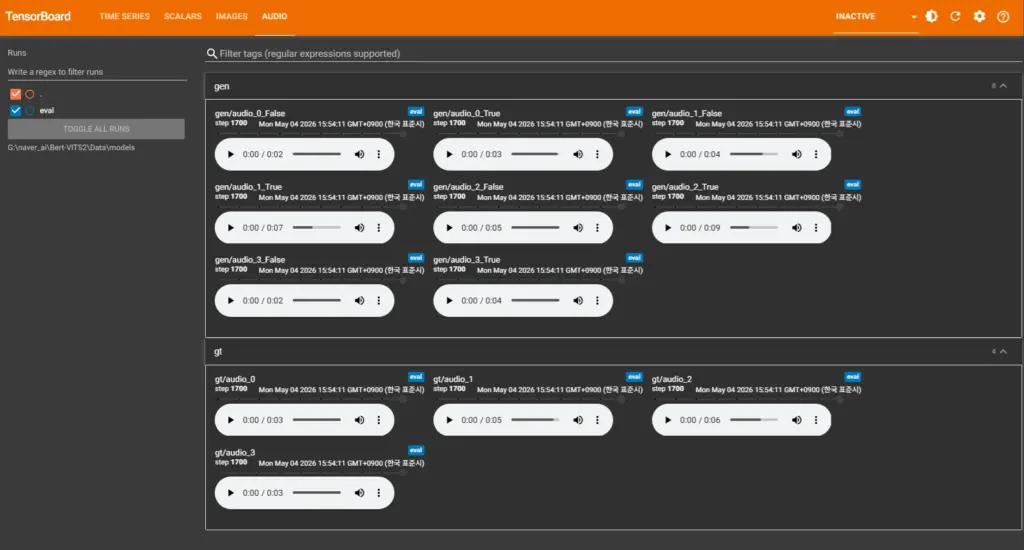
# 별도 터미널에서 실행
tensorboard --logdir Data/models/브라우저에서 http://localhost:6006을 열면 학습 곡선을 실시간으로 확인할 수 있다. Loss 그래프가 전반적으로 감소 추세라면 정상적으로 학습 중인 것이다.
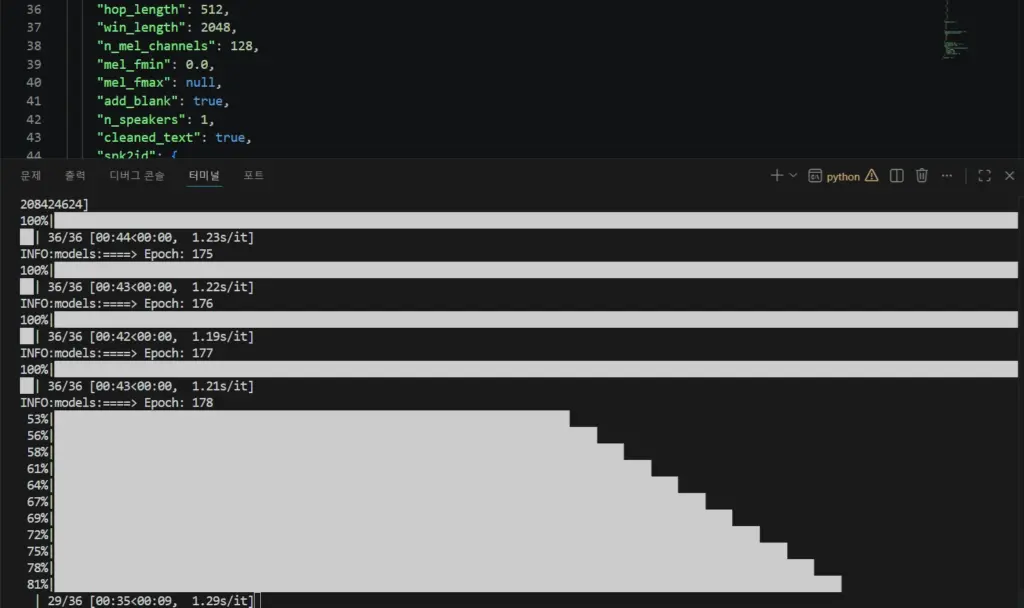
8. 학습 파라미터 해설 (에포크 · 배치 사이즈)
8-1. 에포크(Epoch) — 얼마나 반복할까?
에포크란 전체 학습 데이터를 한 번 모두 사용하는 단위다. 에포크가 높을수록 모델이 데이터를 더 많이 공부하지만, 지나치면 과적합(overfitting) — 실제 데이터는 못 따라가고 학습 데이터만 외워버리는 현상 — 이 발생할 수 있다.
Bert-VITS2 파인튜닝 에포크 가이드
| 데이터 양 | 권장 에포크 | 설명 |
|---|---|---|
| 적음 (50~100문장) | 100 ~ 200회 | 데이터가 적으므로 더 많이 반복해 특징을 최대한 학습 |
| 중간 (300~500문장) | 50 ~ 100회 | 가장 이상적 구간 — 목소리 특징이 잘 잡힘 |
| 많음 (1,000문장 이상) | 30 ~ 50회 | 데이터 자체가 많아 적은 반복으로도 정교해짐 |
실용 팁: 학습 중간중간(
G_500.pth,G_1000.pth등)에 저장되는 체크포인트로 추론을 테스트해보며 최적 에포크를 직접 확인하는 것이 가장 좋다.
8-2. 배치 사이즈(Batch Size) — 메모리와의 균형
배치 사이즈는 한 번의 가중치 업데이트에 사용하는 샘플 수다. 클수록 학습이 안정적이지만 VRAM을 더 많이 사용한다.
| GPU VRAM | 권장 배치 사이즈 | 비고 |
|---|---|---|
| 6GB (RTX 2060 기본) | 2 | --num_workers 0 함께 사용 권장 |
| 8GB (RTX 3070 등) | 4 | 안정적인 학습 가능 |
| 12GB (RTX 3080 등) | 6 ~ 8 | 최적 품질 |
| 24GB (RTX 3090/4090) | 16 이상 | 매우 빠른 학습 |
8-3. 학습 시간 예측
RTX 2060(6~12GB) 기준, 데이터 30분 분량(약 180~360 파일) 기준:
| 에포크 | 예상 학습 시간 | 결과물 품질 |
|---|---|---|
| 50회 | 약 30분~1시간 | 목소리 특성 어느 정도 반영 |
| 100회 | 약 1~2시간 | 쓸만한 수준 |
| 200회 | 약 3~5시간 | 실사에 가까운 품질 |
| 500회 | 약 8~12시간 | 최고 품질 (과적합 주의) |
9. 학습 완료 후 — 모델 추론 및 코드 이식
9-1. 생성되는 핵심 파일
학습이 완료(또는 중간 체크포인트)되면 아래 파일들이 생성된다:
| 파일명 | 역할 |
|---|---|
G_1000.pth | 생성기(Generator) 모델 — 내 목소리의 “지문” |
D_1000.pth | 판별기(Discriminator) 모델 — 추론 시에는 필요 없음 |
config.json | 모델 구성 파일 — 반드시 함께 보관 |
숫자(
1000)는 해당 스텝에서 저장됐다는 의미다. 가장 마지막 G 파일이 가장 많이 학습된 모델이다.
9-2. 추론(Inference) 코드 예시
학습된 모델로 텍스트를 즉시 음성으로 변환하는 기본 추론 코드
import torch
import commons
import utils
import numpy as np
import soundfile as sf
import os
from models import SynthesizerTrn
from text.cleaner import clean_text
from text import cleaned_text_to_sequence
# ---------------------------
# 경로 설정
# ---------------------------
base_path = r"G:\naver_ai\Bert-VITS2"
model_path = os.path.join(base_path, "Data/models/G_17900.pth")
config_path = os.path.join(base_path, "configs/config.json")
device = "cuda" if torch.cuda.is_available() else "cpu"
# ---------------------------
# 모델 로드
# ---------------------------
hps = utils.get_hparams_from_file(config_path)
net_g = SynthesizerTrn(
112, # 반드시 학습과 동일
hps.data.filter_length // 2 + 1,
hps.train.segment_size // hps.data.hop_length,
n_speakers=hps.data.n_speakers,
**hps.model,
).to(device)
checkpoint = torch.load(model_path, map_location=device)
net_g.load_state_dict(checkpoint["model"], strict=False)
net_g.eval()
# ---------------------------
# 음성 생성 함수
# ---------------------------
def generate_voice(text, output_path):
# 핵심: language는 반드시 "KR"
norm_text, phones, tones, word2ph = clean_text(text, "KR")
phone_ids, tone_ids, lang_ids = cleaned_text_to_sequence(phones, tones, "KR")
# ---------------------------
# intersperse (학습과 동일)
# ---------------------------
if hps.data.add_blank:
phone_ids = commons.intersperse(phone_ids, 0)
tone_ids = commons.intersperse(tone_ids, 0)
lang_ids = commons.intersperse(lang_ids, 0)
x = torch.LongTensor(phone_ids).unsqueeze(0).to(device)
x_len = torch.LongTensor([len(phone_ids)]).to(device)
t = torch.LongTensor(tone_ids).unsqueeze(0).to(device)
l = torch.LongTensor(lang_ids).unsqueeze(0).to(device)
# ---------------------------
# BERT 완전 제거 (네 모델은 BERT 없이 학습됨)
# ---------------------------
total_len = len(phone_ids)
dummy_bert = torch.zeros(1, 1024, total_len).to(device)
with torch.no_grad():
audio = (
net_g.infer(
x=x,
x_lengths=x_len,
sid=torch.LongTensor([0]).to(device),
tone=t,
language=l,
bert=dummy_bert,
ja_bert=dummy_bert,
en_bert=dummy_bert,
sdp_ratio=0.2,
noise_scale=0.6,
noise_scale_w=0.8,
length_scale=1.0,
)[0][0, 0]
.cpu()
.float()
.numpy()
)
sf.write(output_path, audio, hps.data.sampling_rate, subtype="PCM_16")
print(f"완료: {output_path}")
# ---------------------------
# 실행
# ---------------------------
if __name__ == "__main__":
generate_voice(
" 활기차게 읽어야 되는데 이 부분을 잘 처리를 못 하겠어요 ",
"final.wav",
)9-3. 기존 SoVITS 코드와의 비교
| 항목 | SoVITS 서버 방식 | Bert-VITS2 로컬 방식 |
|---|---|---|
| 추론 속도 | 네트워크 레이턴시 포함 | 거의 실시간 |
| 서버 필요 여부 | 필요 | 불필요 |
| 설치 복잡도 | 별도 서버 설정 | 단일 프로세스 |
| 품질 | 높음 | 동등 또는 이상 |
10. 사전 학습 모델(Pretrained Model) 체크리스트
사전 모델은 AI의 ‘목소리 뼈대’입니다. 이 단계가 틀리면 아무리 오래 학습해도 기계음만 나온다.
10-1. 필수 파일 구성 (v2.3 기준)
Data/models 폴더 안에 아래 3(또는 4)개 파일이 반드시 있어야 한다.
G_0.pth: 목소리 생성의 핵심 (가장 큰 용량)D_0.pth: 음질 및 판별 관련DUR_0.pth: 말하기 속도 및 박자 (v2.3 필수)WD_0.pth(선택): 일부 모델에 포함된 보조 파일
10-2. 버전 및 규격 확인
사용자님의 설정(config.json)과 모델의 스펙이 일치해야 한다.
- 용량 확인:
G_0.pth가 700MB~850MB 사이라면 v2.3이 확실합니다. (200MB 이하는 구버전입니다.) - 설정값 확인:
config.json의"gin_channels"가 512인지 꼭 확인하세요. v2.3 사전 모델의 표준입니다. - 언어 확인: 한국어 학습 시, 한국어(KO) 혹은 다국어(Multi-lingual) 모델을 쓰는 것이 발음이 가장 정확합니다.
11. 한국어 사전 모델을 올바르게 넣고 시작하는 법
Bert-VITS2 v2.3 한국어 전용 사전 모델이 있으면 반드시 모델을 지정한다. 새로운 학습을 시작하거나 모델을 교체할 때 이 순서를 따르는다. 한국어 모델은 아직 배포 버전이 없는거 같다 현재 작업이 완료 되면 공유할 계획이다.
Bert-VITS2 v2.3 한국어 전용 사전 모델을 확인하기
11-1. Step 1: 폴더 청소 (Clean Start)
G:\naver_ai\Bert-VITS2\Data\models 폴더로 이동하여 번호가 붙은 모든 파일(G_1000.pth 등)과 로그 파일(events...)을 삭제하기.
이유: 기존 실패 기록이 남아있으면 새로 넣은 사전 모델을 덮어씌워 버릴 수 있다.
11-2. Step 2: 사전 모델 배치
pretrained_models 폴더에 보관 중인 진짜 사전 모델(G_0.pth, D_0.pth, DUR_0.pth)을 Data/models 폴더로 복사한다.
11-3. tep 3: 실행 및 로그 검증
학습 명령어를 입력한 후, 터미널 창을 위로 올려 다음 문구를 반드시 확인하기
| 로그 내용 | 의미 | 상태 |
Loaded checkpoint '...G_0.pth' (iteration 0) | 사전 모델을 성공적으로 읽음 | 성공 (완벽) |
ERROR: emb_g.weight is not in... | 화자 수 설정만 다를 뿐, 뼈대는 읽음 | 진행 가능 (양호) |
Saving model... at iteration 1 | 사전 모델 못 찾음 (0부터 시작) | 즉시 중단 (실패) |
- 배치 사이즈(Batch Size): 최소 4 이상으로 설정하세요. 2로 하면 학습이 너무 불안정해서 소리가 깨질 확률이 높다.
- 평가음(Eval) 듣기: 학습 중
Data/models/eval폴더에 생기는.wav파일을 500 Step 단위로 들어본다.- 정상: 웅얼거리더라도 사람의 음색이 들림.
- 비정상: 아예 아무 소리 안 나거나, “뚜두두” 소리만 반복됨.
12. 부록 — 실무용 한국어 불용어 목록
한국어 TTS 텍스트 전처리나 NLP 텍스트 정제 작업 시 사용할 수 있는 실무용 불용어 리스트다.
⚠ 중요: 한국어 불용어에는 공식 표준 전체 목록이 존재하지 않는다. 아래는 실무에서 널리 사용되는 기본형 리스트이며, 작업 목적에 따라 선별적으로 사용해야 한다. 예를 들어
아주,너무,전혀같은 단어는 감성분석에서는 제거하면 안 되는 핵심 신호다.
12-1. 감탄사 및 의성어·의태어
아, 휴, 아이구, 아이고, 어, 오, 예, 네, 아니, 응, 으흠, 흠, 하, 허, 헐, 억, 에, 야, 오호, 흐음12-2. 의존명사 (빈 내용어)
것, 거, 게, 점, 수, 일, 분, 명, 곳, 쪽, 데, 때, 경우, 경우에, 경우의,
생각, 말, 내용, 부분, 정도, 문제, 사실, 상황, 결과, 이유, 원인, 방법, 방식,
형태, 종류, 대상, 이유로, 관점, 의미, 목적, 필요, 이유가, 경우를, 경우가12-3. 지시·대명사
이, 그, 저, 이거, 그거, 저거, 이것, 그것, 저것, 이들, 그들, 저들,
여기, 거기, 저기, 이쪽, 그쪽, 저쪽, 이곳, 그곳, 저곳,
이런, 그런, 저런, 이렇다, 그렇다, 저렇다, 이런저런,
각자, 서로, 누구, 무엇, 뭐, 아무, 어느, 어느정도, 어느새,
이만큼, 그만큼, 저만큼12-4. 인칭대명사
나, 너, 저, 저희, 우리, 당신, 본인, 자신, 자기, 자신들,
누가, 누군가, 아무나, 모두, 전부, 다, 모두들, 여러분,
사람, 사람들, 인간, 자, 자들12-5. 조사
은, 는, 이, 가, 을, 를, 에, 에서, 에게, 한테, 께, 와, 과, 하고, 랑, 이랑,
으로, 로, 에서의, 에게서, 에게로, 로서, 로써,
보다, 만큼, 만, 밖에, 뿐, 조차, 마저, 까지, 부터,
에서부터, 에까지, 에다가, 마다, 쯤, 만치, 치고,
통해, 통한, 통하여, 대한, 대하여, 관련, 관련된,
의, 의한, 위한, 에의, 에서의, 으로의, 로의,
도, 만, 조차, 마저, 뿐, 밖에, 만큼, 나마, 든지, 든가12-6. 접속사·부사
그리고, 그러나, 하지만, 그런데, 그렇지만, 또한, 또는, 혹은,
즉, 곧, 즉시, 다시, 또, 더, 덜, 오히려, 게다가, 더구나,
따라서, 그래서, 그러므로, 그러니, 그러면, 그러니까,
반면, 반대로, 대신12-7. 정도·빈도 부사
혹시, 아마, 대개, 보통, 자주, 가끔, 때때로, 종종, 늘, 항상,
거의, 매우, 너무, 꽤, 상당히, 무척, 별로, 전혀, 전부, 모두,
완전히, 대충, 얼추, 약간, 조금, 좀, 아주, 참, 정말, 진짜, 너무나, 하도12-8. 고빈도 동사·형용사 (문맥 의존)
하다, 되다, 있다, 없다, 아니다, 되었다, 있었다, 없었다, 하였다,
한다, 한다고, 하고, 하며, 해서, 해도, 해, 했, 할, 될, 됨, 함,
보다, 같다, 같은, 같음, 같아, 있다면, 없으면, 아니면12-9. 시간·수량 표현
년, 월, 일, 시, 분, 초, 주, 개월, 동안, 사이, 시기, 시점,
이후, 이전, 현재, 지금, 오늘, 어제, 내일,
한, 하나, 둘, 셋, 넷, 다섯, 여섯, 일곱, 여덟, 아홉, 열,
백, 천, 만, 억, 조12-10. 기타 연결 표현
위해, 위하여, 통해, 통하여, 따라서, 때문, 때문이다, 탓, 덕분,
만큼의, 정도, 가량, 쯤, 정도로, 정도의,
및, 등, 등등, 따위, 포함, 포함된, 포함하여, 비롯, 비롯한,
각, 각종, 여러, 여러가지, 모든, 온갖, 각각,
-다, -다며, -다고, -다는, -다면, -다기, -다든가, -다거나12-11. 실행에 필요한 최소 구조
Bert-VITS2/
├── configs/
│ └── config.json ← 필수 (모델 설정)
├── bert/ ← 필수 (다국어 BERT)
├── text/ ← 필수 (텍스트 처리)
├── monotonic_align/ ← 필수 (정렬 알고리즘)
├── G_143000.pth ← 필수 (학습된 모델)
├── infer.py ← 필수 (추론 실행)
├── models.py ← 필수 (모델 정의)
├── utils.py ← 필수 (유틸리티)
├── commons.py ← 필수 (공통 함수)
├── mel_processing.py ← 필수 (멜 스펙트로그램)
├── attentions.py ← 필수 (어텐션 모듈)
├── modules.py ← 필수 (모듈 정의)
└── transforms.py ← 필수 (변환 함수)
주의 사항
학습이 이미 진행되고 있는 상태에서 train.list, val.list, 또는 short_character_anno.list 같은 데이터를 중간에 수정하면, 모델 입장에서는 동일한 step에서 데이터가 갑자기 바뀌는 상황이 된다. 이는 이전에 학습한 패턴과 충돌하여 발음이 흔들리거나, loss가 튀거나, 이상한 음성이 출력되는 원인이 된다. 특히 데이터 규모가 작을수록 이러한 변화에 민감하여 몇 줄의 수정만으로도 전체 학습 방향이 어긋난다.
따라서 원칙은 명확하다. 학습을 시작했다면 데이터는 끝까지 그대로 유지해야 하며, 수정이 필요하다면 반드시 학습을 중단하고 데이터를 재정리한 뒤 처음부터 다시 학습을 진행해야 한다.
1. AI는 글자가 아닌 소리를 학습한다
AI(Bert-VITS2) 모델에게 텍스트를 제공하는 목적은 특정 글자를 보고 그에 맞는 소리를 내도록 학습시키기 위함이다.
- 국물로 작성할 경우: AI는 표기대로 [국.물.]이라고 발음하는 법을 배운다. 이것이 외국인 말투가 나타나는 주요 원인이다.
- 궁물로 작성할 경우: AI는 한국인이 실제로 말하는 자연스러운 소리인 [궁물]을 학습한다.
만약 모든 표기를 표준 맞춤법에 맞춰 “국물”로 수정했다면, AI는 한국어를 음절 단위로 끊어서 딱딱하게 읽는 것으로 잘못 학습하게 된다.
2. 엔진(g2pk)의 역할과 활용
엔진을 업그레이드하는 이유는 사람이 일일이 “궁물”, “실라(신라)”, “해돋이(해도지)”와 같이 구어체로 변환하여 입력하기 어렵기 때문이다. 중간에서 엔진이 “국물”을 “궁물”로 변환하여 AI에게 전달하는 역할을 수행한다.
- 학습 데이터(transcript.list): 가급적 소리 나는 대로 적혀 있는 것이 학습 효율 측면에서 가장 유리하다.
- 실제 사용(Inference): “국물”이라고 입력하더라도 내부 엔진이 실시간으로 “궁물”로 변환하여 모델에 전달해야 발음이 꼬이지 않고 자연스럽게 출력된다.
g2pk (Grapheme-to-Phoneme for Korean)
현재 사용 중인 엔진은 g2pk라는 한국어 전용 발음 변환 엔진이다.
- 성능: 오픈소스 환경에서 한국어 발음 규칙(비음화, 유음화, 연음, 된소리 등)을 가장 정확하게 구현한 최상급 엔진에 속한다.
- 특징: 단순히 글자를 분리하는 수준을 넘어, 앞뒤 글자의 관계를 분석해 실제 구어체 소리로 문장을 재구성한다.
- 예시: “입 냄새” → 엔진 통과 → “임 냄새” (실제 한국인 발음 방식)
기존 방식과의 차이 (Whisper 원문 사용)
기존에는 Whisper가 받아쓰기한 결과물을 가공 없이 학습에 그대로 활용했다.
- 문제점: Whisper는 지능이 높아 “궁물”이라는 소리를 들어도 맞춤법에 맞는 “국물”로 기록한다. 하지만 TTS 모델(Bert-VITS2)은 이 텍스트를 보고 정직하게 “국.물.”이라고 읽는다.
- 결과: 한국어 특유의 부드러운 연결 발음을 학습하지 못해, 한국어를 갓 배운 외국인이 사전을 읽는 듯한 딱딱한 말투가 형성되었다.
| 비교 항목 | 기존 방식 (Whisper 원문) | 현재 방식 (g2pk 엔진) |
| 텍스트 형태 | “듣는 사람도 불쾌하면…” | “든는 사람도 불쾌하면…” |
| 학습 지시 | 표기된 글자 그대로 읽도록 학습 | 실제 말하는 소리대로 읽도록 학습 |
| 발음 스타일 | 딱딱함, 외국인 말투, 끊어 읽음 | 부드러움, 한국인 억양, 자연스러운 연결 |
| 학습 효율 | 모델이 발음 규칙을 스스로 추론해야 함 | 정확한 발음 정보를 미리 제공하여 학습 속도가 빠름 |
1. BERT의 활용 (문맥 파악의 핵심)
이미 bert_gen.py를 실행한 것은 매우 중요한 과정이다. 한국어에는 글자는 같으나 뜻이 다른 동음이의어가 많기 때문이다.
- 예시: “밤에 밤을 먹었다.”
- BERT의 역할: 앞의 ‘밤’은 시간(Time)으로, 뒤의 ‘밤’은 음식(Chestnut)으로 파악한다.
- 결과: BERT를 통해 AI는 단순한 글자 읽기를 넘어 문장의 의미를 이해하며, 그에 적합한 강세와 억양을 부여한다. 현재 전처리 과정에 BERT가 포함되어 있다면 올바른 방향으로 진행 중인 것이다.
2. 쉼표(,)와 마침표(.)의 활용
학습 데이터를 생성하거나 향후 TTS로 문장을 제작할 때 쉼표를 적절히 활용하는 것이 좋다.
- 방법: “든는 사람도 유패야 농다미지에” 보다는 “든는 사람도 유패야, 농다미지에,”와 같이 쉼표를 삽입한다.
- 효과: 쉼표는 AI가 숨을 고르는 구간(Pause)을 형성한다. 문장이 길어질 때 발생하는 급박한 전개를 방지하며, 훨씬 인간적인 리듬감을 구현한다.
3. 영어를 한글 발음으로 강제 변환
g2pk가 기본적인 영어 처리를 지원하지만, 특수한 브랜드명이나 약어에서 오독이 발생할 수 있다.
- 팁:
OpenIPC→오픈아이피씨,VITS→비츠와 같이 아예 한글로 풀어서 학습 데이터에 기입하는 방식이 가장 확실하다. - 적용: 리스트에 이미 ‘비맥스’처럼 변환되어 있다면 그대로 유지한다. 영어가 원문 그대로 남아있는 행이 있다면 한글 발음으로 수정할 것을 권장한다.
4. 오디오 정규화 (Normalization)
현재 pydub을 이용해 파일을 분할한 상태에서, 개별 파일 간의 볼륨(음압) 차이가 크면 AI 학습에 혼선을 줄 수 있다.
- 기술적 보완: 모든 오디오의 볼륨을 일정하게 맞추는 정규화 작업을 거치면 목소리 톤이 튀지 않고 균일해진다.
- 진행 방향: 우선 현재 상태로 학습을 진행한 뒤, 결과물에서 목소리 크기가 들쭉날쭉하다면 이 단계를 추가하는 방향으로 검토한다.
Bert-VITS2 주요 학습 지표 분석로그
로그에 찍히는 각 숫자들은 모델이 목소리의 어떤 요소를 학습하고 있는지를 나타냅니다.
| 순서 | 예시 숫자 | 명칭 | 실제 의미 (누구나 알기 쉽게) | 체크 포인트 |
| 1번 | 2.48 | Loss G | 전체적인 목소리 완성도 | 2~3점대면 아주 양호합니다. |
| 2번 | 2.25 | Loss FM | 목소리의 특징(지문) 일치도 | 낮을수록 원래 목소리와 똑같아집니다. |
| 3번 | 7.59 | Loss Dur | 말하기 속도와 리듬 (박자) | 가장 중요! 10 이하로 관리되어야 합니다. |
| 4번 | 19.62 | Loss Diff | 목소리의 선명도와 디테일 | 15~25 사이면 정상입니다. |
| 5번 | 2.45 | Loss Mel | 음색(톤)의 정확도 | 학습 초기에 비해 숫자가 낮아져야 합니다. |
| 6번 | 1.83 | Loss Kl | 데이터 정규화 (안정성) | 1~3 사이에서 안정적으로 노는 게 좋습니다. |
| 7번 | 44090 | Step | 현재까지 학습한 총 횟수 | 현재 4만 번 넘게 학습했다는 뜻입니다. |
| 8번 | 9.99e-06 | LR | 학습 속도 (가속도) | 모델이 얼마나 세밀하게 고치고 있는지 보여줍니다. |
웹으로 쓰고 싶다면
생각보다 별거 없다. 지금까지는 파이썬 파일을 직접 실행해서 결과만 확인했다면, 이제는 그걸 브라우저 화면으로 띄워서 버튼 누르듯 쓰는 방식이라고 보면 된다.
일단 Bert-VITS2 폴더 안에서 실행 파일 하나만 찾아서 실행해주면 된다. 보통 이름은 webui.py나 app.py 같은 식으로 되어 있다. 그래서 터미널에서 하는 일은 단순하다.
python webui.py- 또는
python app.py
이걸 실행하면 뭔가 복잡하게 돌아가는 것 같지만, 실제로는 내부에서 서버를 하나 띄우는 과정이다. 잠깐 기다리면 콘솔에 주소가 하나 찍힌다. 보통 http://127.0.0.1:7860 이런 식이다.
그 주소를 그대로 브라우저에 넣으면 끝이다. 그러면 텍스트 입력하고 바로 음성 들어볼 수 있는 화면이 뜬다. 코드 수정 없이 바로바로 테스트할 수 있어서 훨씬 편해진다
RTX 2060 6GB VRAM으로도 Bert-VITS2 학습이 가능한가
가능하다. 배치 사이즈를 2로 낮추고 --num_workers 0 옵션을 추가하면 6GB VRAM에서도 학습이 진행된다. 단, 12GB 모델보다 학습 속도가 느리고 배치 사이즈가 작아 수렴이 약간 불안정할 수 있다.
녹음 장비가 없어도 되나?
원칙적으로는 깨끗한 마이크 음성이 필요하지만, 이미 존재하는 고품질 팟캐스트 녹음 파일, 스튜디오 녹음본, 전문 강의 녹음 등도 배경음이 없다면 활용 가능하다. 단, 저작권 문제는 반드시 확인해야 한다.
학습 중 CUDA OOM(Out of Memory) 에러가 나면?
configs/config.json에서 batch_size를 현재 값의 절반으로 줄이고 재시작하자. 그래도 안 되면 train_ms.py에서 fp16_run: true 옵션을 활성화해 메모리 사용량을 줄인다.
일본어나 영어도 같이 학습할 수 있나?
가능하다. short_character_anno.list 파일에서 언어 코드를 JP 또는 EN으로 지정하면 된다. 단, 각 언어별로 충분한 데이터가 있어야 품질이 나온다.
GPT-SoVITS와 뭐가 다른가?
GPT-SoVITS는 극소량(1~3분) 데이터로도 제로샷 목소리 복제가 가능하지만, 추론 속도가 느리고 서버 설정이 복잡하다. Bert-VITS2는 30분 이상의 데이터가 필요하지만 추론 속도가 훨씬 빠르고 감정·억양의 자연스러움이 더 뛰어나다.
Bert-VITS2 파인튜닝은 복잡해 보이지만, 정리해보면 세 단계다: 환경 만들기 → 데이터 준비하기 → 학습시키기. 이 세 가지만 제대로 하면, RTX 2060 한 장으로도 사람과 구분이 어려운 한국어 커스텀 TTS를 완성할 수 있다.
가장 중요한 것은 반복해서 강조했듯 데이터의 질이다. 잡음 없는 깨끗한 음성 파일 30분이 최신 모델보다 훨씬 더 큰 영향을 미친다. 학습 환경을 완벽하게 구축하는 데 시간을 쓰기 전에, 좋은 녹음 환경을 먼저 확보하자.
학습이 완료되고 G_1000.pth 파일이 생성되는 순간, 어떤 텍스트든 “내 목소리”로 즉시 말해주는 AI가 완성된다. 뉴스 브리핑, 유튜브 내레이션, 팟캐스트 자동화 등 활용처는 무궁무진하다.
/my_voice_model_v1/
├── G_latest.pth (목소리 가중치 파일)
├── config.json (모델 설정 값)
├── model_info.json (화자 및 버전 정보)
└── README.txt (사용법 및 출처 명기)